Updated March 14, 2023

Introduction to Avro File Format
Avro file format is a row-based repository configuration that can be used for Hadoop, and generally. It can use the data in serial form and this format can reserve the schema in JSON format so that the user can able to read and explain in any program. The whole data can be reserved in JSON format by compressing and well organizing in the avro files, it does not require a particular language because it can be prepared by many languages. This format file can provide strong assistance to data schemas that can substitute over time.
What is Avro file format?
The avro file format is responsible for storing the data in deplaning blocks in which data can be passed block-wise and generally read as a whole and it can be processed further downstream in which we can say that row-oriented formats are more well planned in such types of cases. The avro file format can able to reserve data in JSON format that can be utilized for changing the data so that data can be readable by humans and also can be implemented in the code, by compressing that data can be reserved in binary format and available in avro files. This format cannot use any language as it can be handled by other few languages. It provides robust assistance for data schemas for changing the data.
How avro file format works?
Let us see the working of the avro file format step by step,
- In the general working of the avro, we have to generate the schema and that schema has been outlined as per the data.
- It can also arrange the data by using the serialization API which has been given by avro, and that will be established in the ‘org.apache.avro.specific’ package.
- The data has been reconstructed by using API for it and that has been established in the ‘org.apache.avro.specific’ package.
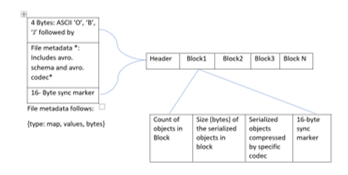
- The file format can work in the landing zone, in which the complete data from the zone has been read in our program, and that can be used for further processing, one by creating a class as per the schema in which the schema has been compiled.
- It can create a class as per the schema, and second, with the help of Parsers library, it means straightly we can able to read the schema with the help of parsers library.
- The related systems can simply able to gain table schema from the avro files which do not have to reserve schema separately.
- As per the evolution of schema the change can be handled by the source.
Create Avro file format
Let us see how to create the avro file and avro can convert our data in JSON or binary format in which our system can only accept the binary files, when we try to create the avro file then we will have data, and JSON file or schema file.
- The avro format has a generous data structure in which we can able to generate records having an array, enumerated type, and a sub-record.
- The avro format will have rich applicants for reserving the data in data lake landing blocks in which each block can object, size, a compressed object.
- The data has been read generally from the leading block and there is no need to reserve schema differently.
- Now see an example of schema which can describe the document in namespace “file format”, and the name is “student”, in which the complete name of it is a ‘file format.student.avsc’.
- The schema file will have a ‘. avsc’ extension so that avro file will be ‘.avro’ after changing the data.
{
"namespace": "fileformat",
"type": "record",
"name": "student",
"fields": [
{
"name": "sid",
"doc": "student id. may be it is stid, esa, yga.",
"type": [
{
"name": "stid",
"type": "long",
"doc": "College stu id."
}
- If we do not have the schema then it can able to give a standard to use and we can adjust the fields and values depending on the requirements.
Command Avro file format:
The ‘sqoop’ command has been used to preserve the data in avro file format in which apache can assist the avro data files, the ‘sqoop’ command has some parameters that we have to add, that are,
- as–avrodatafile – which can be used for importing data to the avro data files.
- compression—codec – which has been used by Hadoop codec.
- The ‘sqoop’ command has its template and we have to import this command we have import bindir and we have to make the connection for it with the help of a template.
- We also have to import the driver up to class manually for specifying the connection manager class.
- If we want to delete the target directory then we can do it by using AWS CLI.
- The ‘sqoop’ command can be used transmit data either from Hadoop or AWS, for querying the data we have to generate the tables on the head of the physical files.
- If the data can transmit through Hadoop, then we have to generate the Hive tables and if the data has been transmitted through AWS then we have to either generate Hive table or tables in Amazon.
If we have an end of the line as HDFS then it allows us to write a command for retrieving the schema of the table as,
‘hadoop jar avro-tools-1.8.1.jar getschema’.
If we have AWS as the end of the line then we have to reprint the avro data file to the contains system and then we can gain the schema,
‘java -jar avro-tools-1.8.1.jar getschema’.
Conclusion
In this article, we conclude that the Avro file format can reserve data in row form in which users can read and interpret that data, so we have also discussed how to create file format, how Avro file format works, and also seen the commands for the Avro file format.
Recommended Articles
This is a guide to Avro File Format. Here we discuss the introduction, What is Avro file format, How to work avro file format?. You may also have a look at the following articles to learn more –
