Updated March 15, 2023
Introduction to TensorFlow Quantization
The following article provides an outline for TensorFlow quantization. The practice of lowering the number of bits that make up a number and are used to express a model’s parameters is known as quantization. The parameters of a model in TensorFlow, for example, are 32-bit floating-point values by default. TF Lite is a suite of tools for optimizing models. It can be used in conjunction with conventional TensorFlow to minimize the size of the trained TF models and hence improve their efficiency.
TensorFlow quantization overviews
The most straightforward reason for quantization is to reduce file sizes by recording the min and max values for each layer and then compressing each float value to an eight-bit integer indicating the nearest real number in a linear set of 256 inside the range. In the -3.0 to 6.0 range, for example, a 0 byte represents -3.0, a 255 represents 6.0, and 128 represents around 1.5.
Float 32 in ML model
tf.keras.backend.floatx()
'float32'
Said, it’s a means of encoding real numbers (m.k.m., values like 1.348348348399…) that ensures processing speed while minimizing range and precision trade-offs. On the other hand, integer numbers can only be round (say, 10, 3, or 52).
Model TensorFlow Quantization
Therefore, if we wish to deploy our model, the knowledge that it was trained using float32 won’t help us as it increases the model’s size and renders inference less efficient. This difficulty can be solved with the use of quantitative analysis. “It operates by decreasing the precision of the numbers used to represent a model’s parameters,” according to TensorFlow (n.d.). Consider: However, converting the value to 3452 requires only an 8-bit integer, int8, which means we may save 24 bits for displaying the float’s estimate!
Types of Neural Network Quantization
Quantization methods for neural networks
When it comes to neural network quantization, there are two basic approaches: 1) quantification after training and 2) quantization-aware training
post-training quantization
The most widely utilized method of quantization is post-training quantization. Quantization occurs only after the model has completed training in this approach. With little loss in model fidelity, post-training quantization is a conversion approach that can minimize model size while decreasing CPU and hardware accelerator latency. We need to know each parameter’s range, i.e., weights and activations before we can perform post-training quantization. The quantization engine determines the frequency of activations by calculating the activations for each data point in the representative dataset. The quantization engine converts all values within such ranges to lower bit numbers after computing the ranges of both parameters.
Run the following python script to quantify the model weights: frozen graph sample line code
con = tf.lite.TFLiteConverter.from_frozen_graph(frozen_graph_file,
input_arrays=input_arrays,
output_arrays=output_arrays,
input_shapes=input_shapes)
con.allow_custom_ops = True
con.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = con.convert()
Quantization aware training
In quantization-aware training, we introduce this quantization error artificially into the network during training to make it more robust. Backpropagation, a training algorithm on floating-point weights, is still used in quantization-aware training to catch subtle variations. Quantization improves performance by compressing models and lowering latency. The model size shrinks by 4x with the API defaults, and we generally find 1.5 to 4x improvements in CPU latency in the backend tests. Supporting machine learning accelerators, such as the EdgeTPU and NNAPI, will eventually experience latency improvements. The approach produces speech, vision, text, and translation.
In general, quantization-aware training consists of three steps:
- Use tf. Keras to train a standard model.
- Use the relevant API to make it quantization-aware, allowing it to learn certain loss-resistant settings.
- Quantify the model using one of the methods available, such as dynamic range quantization, float16 quantization, or full-integer quantization.
Quantization example
TensorFlow offers built-in support for eight-bit calculations that is suitable for production use. For example, here’s how to convert the newest Google Net model to an eight-bit version: This results in a new version that performs the same operations as the old but with eight-bit computations and quantized weighting.
bazel build tensorflow/demo/label_image:label_image
bazel-bin/tensorflow/demo/label_image/label_image \
--input_graph=/tens/quantized_graph.pb \
--input_width=299 \
--input_height=299 \
--mean_value=128 \
--std_value=128 \
--input_layer_name="Mul:0" \
--output_layer_name="softmax:0"
Example – 2
A trained TensorFlow model is required to quantize the model. So, let’s train a basic CNN model and compare the original TensorFlow model’s accuracy to the transformed model with quantization.
Tensor model implementation ts
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import numpy as np
tf.__version__
Loading a data set:
Here I’m going to use the CIFAR-10 dataset. The class labels are listed below, along with their normal integer values.
0 is an airplane, 1 is a car, 2 is a bird, 3 is a cat, 4 is a deer, and 5 is a dog, 6 is a frog, seven horses, 8: ship,9 is truck
from matplotlib import pyplot
from keras.datasets import cifar10
(trainX, trainy), (testX, testy) = cifar10.load_data ()
print ('Train Analysis: X=%s, y=%s' % (trainX.shape, trainy.shape))
print ('Test Analysis: X=%s, y=%s' % (testX.shape, testy.shape))
train_X, test_Y = train_X / 255.0, test_Y / 255.0
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
// Model
model = models. Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add (layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_X, train_Y, epochs=10,
validation_data=(test_X, test_Y))
Using Float16 Quantization
Float16 quantization decreases the model’s size by converting the weight values to float16 bit floating-point integers with minimal influence on precision and latency. The model size is cut in half using this quantization technique.
convtr = tf.lite.TFLiteConverter.from_keras_model(model)
convtr.optimizations = [tf.lite.Optimize.DEFAULT]
convtr.target_spec.supported_types = [tf.float16]
tflite_model = convtr.convert()
open("converted_model.tflite", "wb").write(tflite_model)
Explanation
Here we have explored models with the quantization, and the results are shown below:
Output
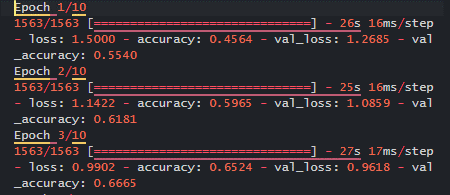
249936
Conclusion
In this post, we looked into TensorFlow quantization approaches that enhance storage requirements and different types of quantization with an example. Finally, we discussed quantization-aware training, which may be done before quantization to build models more resilient to quantization loss by simulating quantization during training.
Recommended Articles
This is a guide to TensorFlow quantization. Here we discuss the tensor flow quantization approaches that enhance storage requirements and different types with an example. You may also have a look at the following articles to learn more –
