Updated March 10, 2023

Introduction to SQL Table Partitioning
Table partitioning in standard query language (SQL) is a process of dividing very large tables into small manageable parts or partitions, such that each part has its own name and storage characteristics. Table partitioning helps in significantly improving database server performance as less number of rows have to be read, processed, and returned. We can use partitioning techniques for dividing indexes and index-organized tables also.
Table partitioning can be of two types, namely, vertical partitioning or horizontal partitioning. In vertical partitioning, we divide the table column-wise. While in horizontal partitioning we divide the table row-wise.
Vertical Partitioning:
e_transactions :
|
order_status :
|
As shown in the illustration above, the e-transactions table has been vertically partitioned and a new partition called “order_status” with columns such as order_id, ordered_at, and shipped_at has been created. Next, let’s have a look at horizontal partitioning.
Horizontal Partitioning:
e_transactions :
| order_id | ordered_at | shipped_at | order_amount | customer_id |
| AJ202001 | 2020-07-01 15:48:25.223 | 2020-07-02 | 4315 | CA01 |
| AJ202001 | 2020-07-02 10:48:00.000 | 2020-07-06 | 4315 | CA01 |
| AJ202004 | 2020-07-02 10:48:00.000 | 2020-07-05 | 5460 | CA06 |
| AJ202003 | 2020-06-30 06:28:00.000 | 2020-07-02 | 1462 | CA05 |
| AJ202005 | 2020-07-01 06:18:00.000 | 2020-07-03 | 15646 | CA032 |
| AJ202002 | 2020-07-01 05:10:00.000 | 2020-07-04 | 1978 | CA07 |
Partitions :
orders_30_06_2020 :
| order_id | ordered_at | shipped_at | order_amount | customer_id |
| AJ202003 | 2020-06-30 06:28:00.000 | 2020-07-02 | 1462 | CA05 |
orders_1_07_2020 :
| order_id | ordered_at | shipped_at | order_amount | customer_id |
| AJ202001 | 2020-07-01 15:48:25.223 | 2020-07-02 | 4315 | CA01 |
| AJ202005 | 2020-07-01 06:18:00.000 | 2020-07-03 | 15646 | CA032 |
| AJ202002 | 2020-07-01 05:10:00.000 | 2020-07-04 | 1978 | CA07 |
orders_2_07_2020 :
| order_id | ordered_at | shipped_at | order_amount | customer_id |
| AJ202001 | 2020-07-02 10:48:00.000 | 2020-07-06 | 4315 | CA01 |
| AJ202004 | 2020-07-02 10:48:00.000 | 2020-07-05 | 5460 | CA06 |
As shown in the illustration, when we partition a table horizontally it’s done row-wise based on the value of a particular column. In this case, we chose the date part of ordered_at column. Three different partitions have been prepared.
Syntax and parameters
The basic syntax for partitioning a table using range is as follows :
Main Table Creation:
CREATE TABLE main_table_name (
column_1 data type,
column_2 data type,
.
.
. ) PARTITION BY RANGE (column_2);Partition Table Creation:
CREATE TABLE partition_name
PARTITION OF main_table_name FOR VALUES FROM (start_value) TO (end_value);The parameters used in the above-mentioned syntax are similar to CREATE TABLE statement, except these :
PARTITION BY RANGE (column_2) : column_2 is the field on the basis of which partitions will be created.
partition_name : name of the partition tableFROM (start_value) TO (end_value) : The range of values in column_2, which forms the part of this partition. Note that start_value is inclusive, while end_value is exclusive.
Here is an example to illustrate it further.
Examples of SQL Table Partitioning
Imagine that you are working as a data engineer for an ecom firm that gets a huge number of orders on a daily basis. You usually store data such as order_id, order_at, customer_id, etc. in a SQL table called “e-transactions”. Since the table has a humongous amount of data in it, the low load speed and high return time, etc. have become a problem for data analysts, who use this table for preparing KPIs on a daily basis. What will you do to improvise this table, so that data analysts can run queries quickly?
A logical step would be partitioning the table into smaller parts. Let’s say we create partitions such that the partition stores data pertaining to specified order dates only. This way, we will have less data in each partition, and working with it will be more fun.
We can partition the table using declarative partitioning ie. by using a PARTITION BY RANGE (column_name) function as shown below.
CREATE TABLE e_transactions(
order_id varchar(255) NULL,
ordered_at date NULL,
shipped_at date NULL,
order_amount numeric(18, 0) NULL,
customer_id varchar(255) NULL
) PARTITION BY RANGE( ordered_at);Output:
The table has been successfully created with provisions for partition.
-
Creating Table Partitions
Next, let us create partition tables for e-transactions table.
CREATE TABLE orders_2020_07_01
PARTITION OF e_transactions FOR VALUES FROM ('2020-07-01') TO ('2020-07-02');
CREATE TABLE orders_2020_07_02
PARTITION OF e_transactions FOR VALUES FROM ('2020-07-02') TO ('2020-07-03');Output:
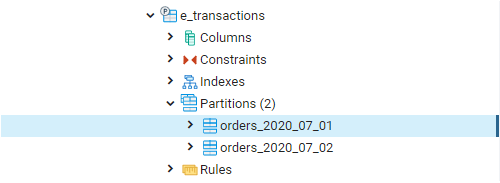
we have successfully created two partitions. The newly created partitions can be seen in the browser window.
Now, let us check the functionality of these table partitions by inserting a few records in the e-transactions table.
INSERT INTO public.e_transactions(
order_id, ordered_at, shipped_at, order_amount, customer_id)
VALUES (1,'2020-07-01','2020-07-02',456,'1'),
(2,'2020-07-02','2020-07-03',631,'1');Output:
Let’s check if the records are stored in designated partitions or not. Our good old friend SELECT statement is here to help us.
SELECT * FROM orders_2020_07_01;Output:

SELECT * FROM orders_2020_07_02;Output:

We can clearly observe from the results of SELECT queries that partitions have been successfully created and used.
-
Removing Table Partitions
Let us assume that we no longer require one of the partitions. We can drop a partition by using the ALTER command.
ALTER TABLE e_transactions DETACH PARTITION orders_2020_07_01;Output:
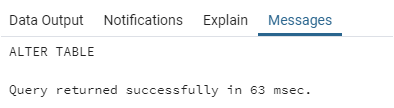
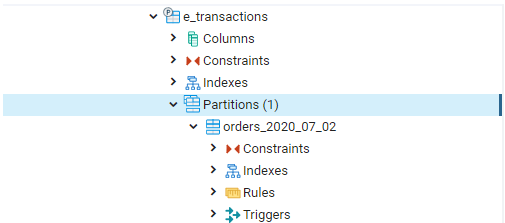
Now, the e_transactions table has only one partition as shown in the image below:
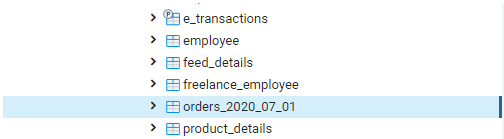
But, the orders_2020_07_01 has become a regular table now.
In this case, we have used the ALTER command to remove a partition from the table but a DROP command can be used instead. However, we should note that the ALTER command will keep the partition table as a regular table after removing it from the partitions of the table, but DROP will remove it from the database. Hence, the former is the most preferred command.
Conclusion
Table partitioning is a method used in relational databases to divide a huge table into several smaller parts. This helps in executing queries on a huge table faster.
Recommended Articles
We hope that this EDUCBA information on “SQL Table Partitioning” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
