Updated March 17, 2023
Introduction to SAS Nodupkey
The SAS Nodupkey is one of the SAS options that helps to check and eliminate the data observations and tracking with a duplicate key or like values specified with the option also by using the procedure like proc sort to compare the existing values, including sort order by variable values on each occurrence and data will be observed continuously the same will be written on the output console screen dataset.

Key Takeaways
- The SAS NODUPKEY and NODUP are the default SAS operations to identify the duplicate set of records in the SAS.
- BY the keyword and PROC Sort is the procedure for performing the sort operations from the data file.
- The noduplicates option is the extended data observations from the following records set.
- The SAS dataset name should be valid for storing and retrieving the records.
- Datas are followed by using the FIRST.value processing like column names.
- Using the NODUPKEY option, the I/O and CPU processing time is less than that of the PROC.SORT operation.
What is SAS Nodupkey?
SAS nodupkey is one of the SAS feature options to eliminate the duplicate set of values already existing through the variable declaration. Using the Procedure option, the sorting order is to be varied and compared to the existing set of values. The proc sort order is eliminated and works similarly to earlier cases. It reduces the memory spaces and cleans up the unwanted data observations, but when compared to Nodeuprecs, it will reach all the sets of every variable by using the key. The nodup option is mainly for checking the data duplicates and observation by using the PROC SORT procedure to achieve the output results; with the help of keys and variables, the nodupkey option is performed.
How to Use the SAS Nodupkey Option?
We know that nodupkey is observed when duplicate data are identified using the By keyword and the variable name the data statement is repeated. Not only for every section of the SAS areas but the duplicate variables are also identified and repeated according to user requirements. When we use NODUPKEY, its to be deleted upto five sets of data observations which helps to identify duplicate sets of values, whereas NODUP has not been performing any delete observations on the SAS. The two identical data records have to be achieved and perform the NODUP option because of the dataset, which helps to look at the data record. The DUPOUT variable option is also used to set the NODUPKEY or NODUP option for the specified dataset.
The first set of variables is assigned as the value, like 1 for each stage of data observations using the BY group of values in all the observation areas. For that, suppose we used the last set of variables like LAST. Variable that can be assigned to the previous observation area, the same as the BY data group, is used. Here, the observation values are 0, similar to the first.variable. Every dataset should be in the sort order; if not, we can use the PROC SORT procedure to sort the datas mainly by using the ID as the unique identifier. And the first and last set of variables are temporary and cannot be used in the newly created dataset; if the dataset is closed and made new, the first and last should be declared new. If the temporary variables are to be visible means, we can create the two sets of variables.
Steps to Create SAS Nodupkey Option
Given below are the steps to create the SAS Nodupkey option:
1. Navigate and log in to the url.
3. Paste the code below to perform the duplicate dataset operation.
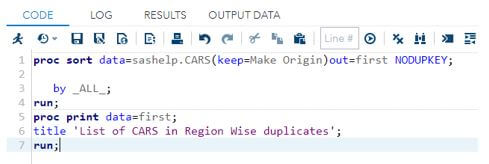
4. proc sort data=sashelp.CARS(keep=Make Origin)out=first NODUPKEY;
5. by _ALL_;
6. run;
7. proc print data=first;
8. title ‘List of CARS in Region Wise duplicates’;
9. run;
10. We get the below output result.
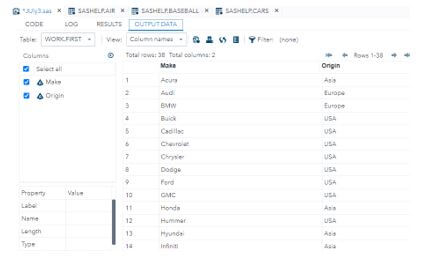
11. Here, we have used SAS.CARS is the class, and the default SAS library helps perform the nodup operation on the dataset.
12. The NODUPKEY and by _ALL_ is the keyword that performs the dataset operation’s sorting procedure.
SAS Nodupkey Checking for Duplicates
The Nodup option is the primary type of feature used in the SORT procedure, which eliminates the data observations already used across the variables. For that, the NODUPKEY is the primary option that removes the values using the BY variable statement; it’s already repeated for identical observations.
It reorders the values for specified data like input and output datasets with valid names like sorted order containing multiple duplicates. The data observations are performed on each set of rows and columns, identifying the unique records set in the user input dataset.
Example of SAS Nodupkey
Given below is the example mentioned:
Code:
proc sort data=sashelp.deskobj(keep=contrcls objtype)out=first NODUPKEY;
by _ALL_;
run;
proc print data=first;
title 'Welcome To My Domain';
run;Output:
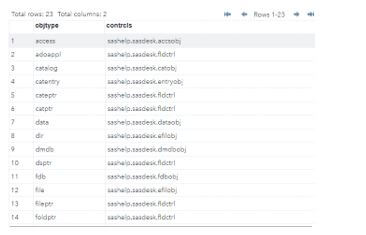
- The above example is the primary example for storing and fetching the nodup operations on SAS.
- It is one way to identify the duplicate set of keys and their values.
- A duplicate set of values caused for to affecting the storage space in the SAS memory space.
- Using the PROC SORT option, the operations are performed by the NODUPKEY and NODUP options.
FAQ
Given below are the FAQs mentioned:
Q1. What are SAS NODUP and NODUPKEY?
Answer:
The SAS NODUP is the option and feature to check and remove the duplicate datas in all the sets of variables. At the same time, the NODUPKEY helps remove the variable listed using the BY Statement.
Q2. What is PROC SORT in SAS NODUPKEY?
Answer:
Proc Sort is the order processing for removing duplicates in the data file using the noduplicates option.
Q3. Define NOUNIQUEKEY in SAS.
Answer:
It helps to remove all the sets of Unique records based on the key variables.
Conclusion
In SAS, multiple ways exist to identify a duplicate set of values which helps to identify the data complexity and ease of usage in another dataset. The Proc Sort order technique eliminates the duplicates like PROC FREQ and PROC SQL query statements for performing the same operations in the SAS.
Recommended Articles
This is a guide to SAS Nodupkey. Here we discuss the introduction, how to use it & steps to create the SAS Nodupkey option with examples and FAQ. You may also have a look at the following articles to learn more –
