
Introduction to Registration Form in HTML
HTML forms are an essential component found across numerous websites today, serving various purposes like user authentication, registrations, feedback collection, and more. These forms facilitate the collection of valuable data and information from visitors to your site.
HTML forms are constructed using special elements known as ‘controls.’ These controls encompass a range of options such as text areas, radio buttons, checkboxes, and submit buttons, enabling users to input their details effectively. Users can modify the provided information by entering texts, selecting specific items, and performing other relevant actions by interacting with these controls. Once the form is completed, it can be submitted, leading to different outcomes such as data addition, transmission, redirection to another page, or even storage of the details in a database.
HTML forms are an interactive and user-friendly means to engage website visitors. They facilitate seamless communication and data exchange between users and website owners, empowering businesses to gather crucial insights and enhance user experience.
How to Create HTML Form?
Creating HTML forms involves using the <form> element, which serves as the container for the form content. Along with other HTML elements, such as <fieldset>, <legend>, and <input>, you can design a fully functional form. Additionally, CSS can be utilized to enhance the appearance and user experience.
The main points discussed in this article for designing a web page in HTML are:
- How to set up your project?
- How to start with the HTML structure?
- How to add content to the body?
- How to structure your content?
- How to save your HTML file?
- How to view your web page?
Following is a basic syntax for an HTML Form.
Syntax:
<form action = "URL" method = "GET or POST">
form elements like submit or reset buttons, input, text area etc.
</form>Example of Registration Form in HTML
Let’s see some examples of registration forms using HTML:
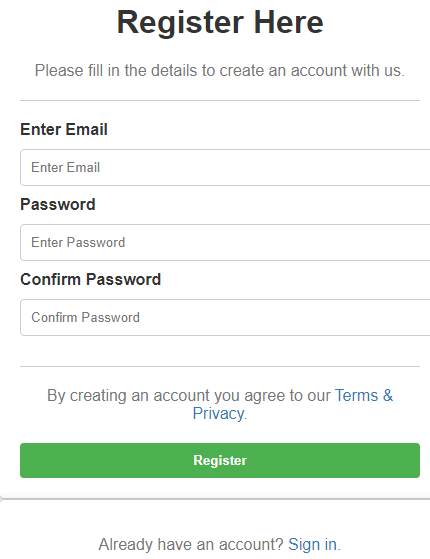
Example 1: Simple Registration Form
Here’s an example of creating a simple HTML registration form.
Code:
<!DOCTYPE html>
<html>
<head>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f2f2f2;
}
.container {
width: 400px;
margin: 0 auto;
padding: 20px;
background-color: #fff;
border: 1px solid #ccc;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
h1 {
text-align: center;
color: #333;
margin-top: 0;
}
p {
text-align: center;
color: #777;
margin-bottom: 20px;
}
label {
display: block;
margin-bottom: 10px;
color: #333;
}
input[type="text"],
input[type="password"] {
width: 100%;
padding: 10px;
margin-bottom: 10px;
border: 1px solid #ccc;
border-radius: 4px;
}
hr {
margin-top: 20px;
margin-bottom: 20px;
border: 0;
border-top: 1px solid #ccc;
}
a {
color: #337ab7;
text-decoration: none;
}
button[type="submit"] {
display: block;
width: 100%;
padding: 10px;
margin-top: 20px;
background-color: #4CAF50;
color: #fff;
border: none;
border-radius: 4px;
cursor: pointer;
font-weight: bold;
}
button[type="submit"]:hover {
background-color: #45a049;
}
.container.signin {
text-align: center;
color: #777;
}
</style>
</head>
<body>
<form>
<div class="container">
<h1>Register Here</h1>
<p>Please fill in the details to create an account with us.</p>
<hr>
<label for="email"><b>Enter Email</b></label>
<input type="text" placeholder="Enter Email" name="email">
<label for="pwd"><b>Password</b></label>
<input type="password" placeholder="Enter Password" name="pwd">
<label for="confirm"><b>Confirm Password</b></label>
<input type="password" placeholder="Confirm Password" name="confirm">
<hr>
<p>By creating an account you agree to our <a href="#">Terms & Privacy</a>.</p>
<button type="submit" class="registerbtn"><strong>Register</strong></button>
</div>
<div class="container signin">
<p>Already have an account? <a href="#">Sign in</a>.</p>
</div>
</form>
</body>
</html>Output:
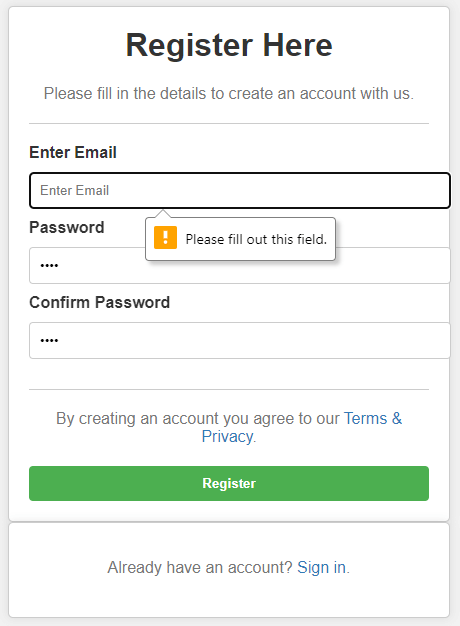
Registration Form: Validations
To ensure users input their email address, we will include a validation code that triggers a pop-up if they attempt to submit the form without completing the email field, regardless of the password and confirmation input.
The keyword ‘required’ with an element indicates that the element must be filled. We will add this keyword to our text field, ‘Email,’ and see the result below;
<input type="text" placeholder="Enter Email" name="email" required>Similarly, you’ll need to do for Password and Confirm Password fields.
<input type="password" placeholder="Enter Password" name="pwd" required>
<input type="password" placeholder="Confirm Password" name="confirm" required>Output:
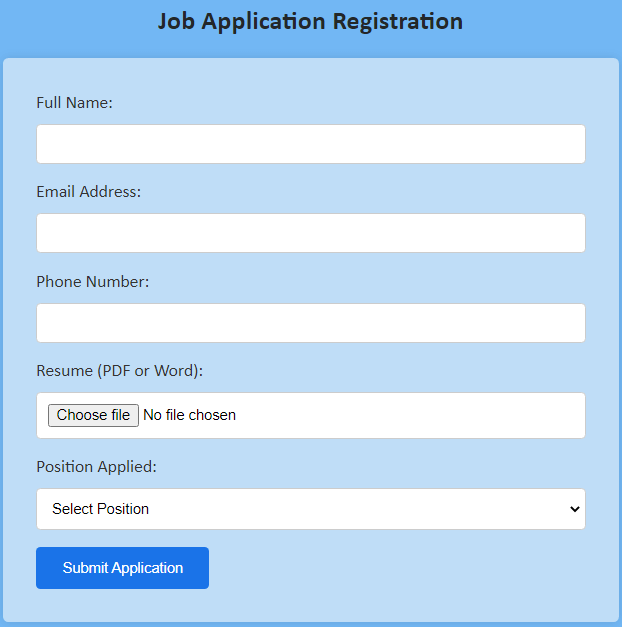
Example 2: Job Application Registration Form
Here’s an example of creating a Job Application Registration Form in HTML.
Code:
<!DOCTYPE html>
<html>
<head>
<title>Job Application Registration Form</title>
<style>
body {
font-family: Calibri, sans-serif;
background-color: #72b7f4;
}
h2 {
color: #232729;
text-align: center; /* Center align the title */
}
form {
background-color: #bfddf7;
max-width: 500px;
margin: 0 auto;
padding: 30px;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
label {
display: block;
margin-bottom: 10px;
color: #333333;
}
input[type="text"],
input[type="email"],
input[type="tel"],
input[type="file"] {
width: 100%;
padding: 10px;
border: 1px solid #cccccc;
border-radius: 4px;
box-sizing: border-box;
margin-bottom: 15px;
background-color: #ffffff; /* Set background color to white */
}
select {
width: 100%;
padding: 10px;
border: 1px solid #cccccc;
border-radius: 4px;
box-sizing: border-box;
margin-bottom: 15px;
}
input[type="submit"] {
background-color: #1a73e8;
color: #ffffff;
border: none;
padding: 12px 24px;
border-radius: 4px;
cursor: pointer;
}
input[type="submit"]:hover {
background-color: #0059b3;
}
</style>
</head>
<body>
<h2>Job Application Registration</h2>
<form action="/apply" method="POST">
<label for="name">Full Name:</label>
<input type="text" id="name" name="name" required>
<label for="email">Email Address:</label>
<input type="email" id="email" name="email" required>
<label for="phone">Phone Number:</label>
<input type="tel" id="phone" name="phone" required>
<label for="resume">Resume (PDF or Word):</label>
<input type="file" id="resume" name="resume" accept=".pdf,.doc,.docx" required>
<label for="position">Position Applied:</label>
<select id="position" name="position" required>
<option value="">Select Position</option>
<option value="frontend-developer">Frontend Developer</option>
<option value="backend-developer">Backend Developer</option>
<option value="graphic-designer">Graphic Designer</option>
</select>
<input type="submit" value="Submit Application">
</form>
</body>
</html>Output:
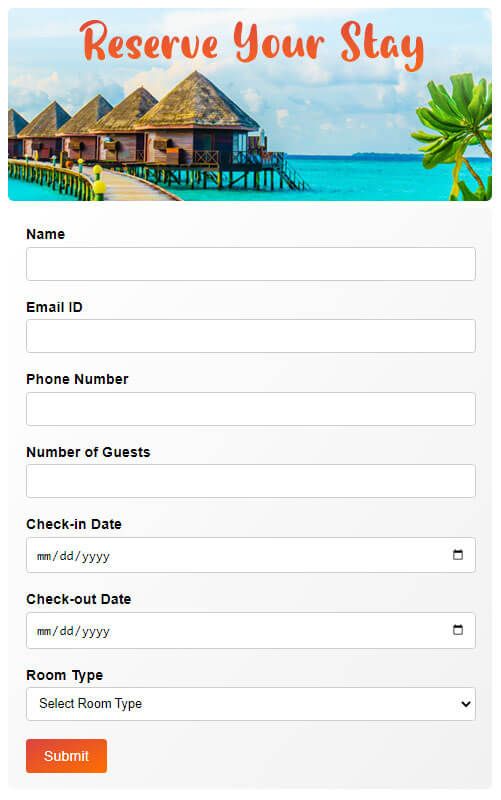
Example 3: Hotel Registration Form
Here’s an example of creating a Hotel Registration Form in HTML.
Code:
<!DOCTYPE html>
<html>
<head>
<title>Hotel Registration Form</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f0bd9d;
padding: 20px;
}
form {
max-width: 500px;
margin: 0 auto;
background: linear-gradient(to bottom right, #fff, #f1f1f1);
padding: 20px;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
label {
display: block;
margin-bottom: 10px;
font-weight: bold;
}
.form-row {
margin-bottom: 20px;
}
.form-row label {
display: block;
margin-bottom: 5px;
}
.form-row input,
.form-row select {
width: 100%;
padding: 10px;
border: 1px solid #ccc;
border-radius: 4px;
box-sizing: border-box;
font-size: 14px;
}
input[type="submit"] {
padding: 10px 20px;
background: linear-gradient(to bottom right, #db4340, #ff6f00);
color: #fff;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 16px;
}
</style>
</head>
<body>
<img src="image.jpg" alt="Hotel Image" style="display: block; margin: 0 auto 20px; width: 500px;">
<form>
<div class="form-row">
<label for="name">Name</label>
<input type="text" id="name" name="name">
</div>
<div class="form-row">
<label for="email">Email ID</label>
<input type="email" id="email" name="email">
</div>
<div class="form-row">
<label for="phone">Phone Number</label>
<input type="tel" id="phone" name="phone">
</div>
<div class="form-row">
<label for="guests">Number of Guests</label>
<input type="number" id="guests" name="guests">
</div>
<div class="form-row">
<label for="check-in">Check-in Date</label>
<input type="date" id="check-in" name="check-in">
</div>
<div class="form-row">
<label for="check-out">Check-out Date</label>
<input type="date" id="check-out" name="check-out">
</div>
<div class="form-row">
<label for="room-type">Room Type</label>
<select id="room-type" name="room-type">
<option value="">Select Room Type</option>
<option value="single">Single</option>
<option value="double">Double</option>
<option value="suite">Suite</option>
</select>
</div>
<input type="submit" value="Submit">
</form>
</body>
</html>Output:
Recommended Articles
This is a guide to the Registration Form in HTML. Here we discuss the introduction, how to create a registration html form, and different examples and code implementation. You may also have a look at the following articles to learn more –

