Updated May 15, 2023

Definition of Redshift Database
Normally Redshift database is a cloud-based solution that is provided by Amazon, we can also call a big data warehouse. The Redshift database provides the storage system to the organization that means the organization can store the data over the cloud and we can easily access any time anywhere as per user requirement and users can access that data through SQL. In another word we can say that clusters and clusters may contain different nodes, the nodes can be accessed independently by the organization and application. Basically, Redshift is designed to be used for different types of tools such as existing SQL.
Syntax:
create database specified database name;
Explanation:
In the above syntax, we used a create database command to create the database, here the specified database name means the actual database name that we need to create.
How database works in Redshift?
Now let’s see how the database works in Redshift as follows.
Basically, database understanding is the fundamental and significant advance that will set up your data set plan on a strong establishment. In light of your database understanding, you can use numerous conditions for your potential benefit just as having the option to settle on educated choices and a reasonable execution vision. The database assists you with setting power over different boundaries, including your normal database stockpiling and even how well questions perform. Set aside an effort to completely comprehend your database and the current connections before you go on to building your inquiries.
Preceding making your data set, you need to set up your Amazon redshift’s bunch and guarantee that everything is going and all around associated with your SQL customer apparatus. A solitary bunch can have numerous database bases.
Suppose you need to assemble a data set for your internet business; first, you’ll need to interface with your underlying data set made when you dispatched your group.
Now let’s see how we can load data into a database as follows.
First, we need to create the database that we want by using the above-mentioned syntax. After that, we need to create the table inside the newly created table by using create table command. After successful creation of the table, we can perform the different operations such as select, insert and drop as per user requirement.
Now let’s see how we can manage the database as well as how we can maintain it as follows.
Database maintenance and management is basically not the most crucial part of the database but it is the most important part of the database process. In database management, we can consider the following points to maintain and manage as follows.
- Always we need to take the backup and also we need to set the backup and recovery.
- We just need to maintain the database table in a timely manner.
- We need to manage workload inefficiently as per requirement.
- Regularly we need to optimize the database queries.
This progression is the thing that guarantees you’ll get the ideal results out of your data set execution just as an expanded execution that advantage from the main elements behind Redshift’s expanded presentation, which are:
- Greatly equal preparing,
- Columnar information stockpiling
- Designated information pressure encoding plans.
Now let’s see what types of operation we can perform on the database as follows.
Alter database operation:
Suppose we need the attribute of an existing database at that time we can alter the database command as per user requirement as follows.
Suppose we need to change the database name at that time we can use the following syntax as follows.
alter database existing specified database name rename to new specified database name;
Suppose if we need to change the database owner at that time we can use the following syntax as follows.
alter database existing specified database name existing owner name to new owner name;
Delete database operation:
Suppose we need to delete the existing database at that time we can use the following syntax as follows.
drop database specified database name;
By using the select clause we can list all existing databases of the Redshift cluster as follows.
select * from pg_database;
Examples
Now let’s see different examples of databases in Redshift for better understanding as follows.
Before the creation of the database, we just need to specify the cluster that means we need to create the cluster as shown in the following screenshot.
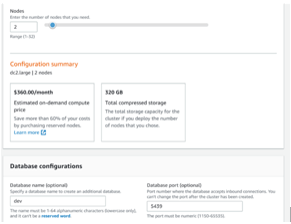
After that, we can connect to the SQL workbench or any other database as per user requirement with help of a JDBC connection
First, let’s see how we can create the database as follows.
Suppose we need to create the database at that time we can use the following statement as follows.
create database sample_red;
Explanation:
In the above example, we use a create a database command to create a new database; here sample_red is the database name that we need to create as shown in the above statement. The final output or we can say that the result of the above statement we can illustrate by using the following screenshot as follows.

But to create the database we need to verify the term that is verifying the running cluster as well we can also create the database with the owner name.
Suppose we need to change the database at that time we can use the following statement as follows.
alter database sample_red rename to red_sample;
Explanation:
In the above example, we use the alter command to rename the existing database name, here we need to change the sample_red database name to red_sample as shown in the above statement. The final output or we can say that the result of the above statement we can illustrate by using the following screenshot as follows.
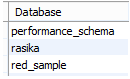
Another use of the alter command is that suppose we need to change the owner name of an existing database at that time we can use the alter database command as per our requirement.
Similarly, we can delete the database by using the drop database command.
Conclusion
We hope from this article you learn more about the Redshift database. From the above article, we have learned the basic concept as well as the syntax of the Redshift database and we also see the different examples of the Redshift database. From this article, we learned how and when we use the Redshift database.
Recommended Article
This is a guide to Redshift Database. Here we discuss the definition, syntax, How database works in Redshift, and examples with code implementation respectively. You may also have a look at the following articles to learn more –

