Updated March 10, 2023

Introduction to Redshift Cluster
Redshift cluster is used to handle a large amount of data, we can create up to 128 node clusters in redshift. Basically, compute node and leader node are the main components available, compute node has its own dedicated CPU, memory and storage device we can execute the query using compute node we can create multiple nodes in a single cluster. The leader node manages the communication between the client application and computes node. Leader node first compiles the code after compiling it will distribute the code to the compute nodes, and then assign data to each node.
Syntax
Given below is the syntax mentioned:
1. Create redshift cluster
- Login to AWS management console
Amazon web services -> Amazon Redshift -> Create cluster
- Amazon configuration
Provide name of cluster identifier -> Select node type -> Select number of node
-> Tick or untick on load sample data
- Database configurations
Provide admin username -> Provide admin user password
- Cluster permissions settings
Provide IAM role name
- Advanced network and security configuration
Provide VPC name -> Provide VPC security group name -> Provide cluster subnet group name -> Provide availability zone name -> Enable or disable the enhanced VPC routing -> Enable or disable the public access of cluster endpoint
- Advanced database configurations
Provide database name -> Provide database port number -> provide parameter group -> Enable or disable the encryption of database
- Maintenance.
Provide the time of maintenance window -> Select the maintenance track.
- Backup of cluster
Select the snapshot backup schedule -> Provide the snapshot retention period -> Enable or disable the cross region snapshot -> Enable or disable the cluster relocation.
- Create cluster
Check all the selected value once -> click on create cluster button.
2. Delete redshift cluster
Select the cluster -> Click on action tab -> Click on delete button -> click on take final snapshot button -> click on delete button.
3. Modify
Select the cluster -> Click on edit tab -> modify the cluster -> click on save changes.
4. Reboot
Select the cluster -> Click on action button -> Click on reboot tab -> click on reboot cluster button.
How Cluster Work in Redshift?
We can create a single as well as a multinode cluster in redshift. Basically, it contains a node. Every redshift cluster contains the leader and computes nodes. At the time of launching, we need to specify the options like node type, the node type which specifies the RAM, CPU and storage capacity of the clusters. On the basis of the node type, the cost is defined.
Following are the node type available in redshift:
RA3 node contains the following node types:
- ra3.xlplus: It will contain the 4 virtual CPU, 32 GB RAM, 32 TB storage space and 2-16 node range.
- ra3.4xlarge: It will contain the 12 virtual CPU, 96 GB RAM, 128 TB storage space and 2-32 node range.
- ra3.16xlarge: It will contain the 48 virtual CPU, 384 GB RAM, 128 TB storage space and 2-128 node range.
Dense node contains the following node types:
- ds2.xlarge: It will contain the 4 virtual CPU, 31 GB RAM, 2 TB storage space and 2-32 node range.
- ds2.xlarge: It will contain the 36 virtual CPU, 244 GB RAM, 16 TB storage space and 2-128 node range.
Dense compute node contains the following node types:
- dc2.large: It will contain the 2 virtual CPU, 15 GB RAM, 160 GB storage space and 1-32 node range.
- dc2.xlarge: It will contain the 32 virtual CPU, 244 GB RAM, 2.56 TB storage space and 2-128 node range.
- dc1.large: It will contain the 2 virtual CPU, 15 GB RAM, 160 GB storage space and 1-32 node range.
- ds1.8xlarge: It will contain the 32 virtual CPU, 244 GB RAM, 2.56 TB storage space and 2-128 node range.
Below are the main parameters which were used at the time of cluster management.
- Analyze threshold percent
- Json configuration
- Statement timeout
- Search path
- Require SSL
- Query group
- Extra float digits
- Enable user activity logging
We can fetch a large amount of data at a fast speed. Also, it is very useful for analytic workloads. Amazon Redshift cluster is linearly scalable for data growth. We can manage using the console.
Examples of Redshift Cluster
Given below are the examples mentioned:
Example #1
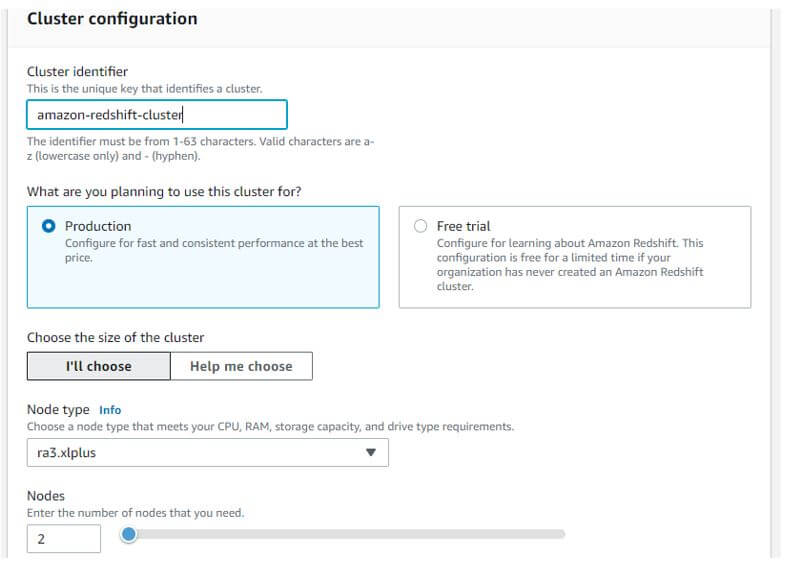
a. First we have configured the cluster information.
Cluster identifier: amazon-redshift-cluster
Node type: ra3xlplus
Nodes: 2
Output:
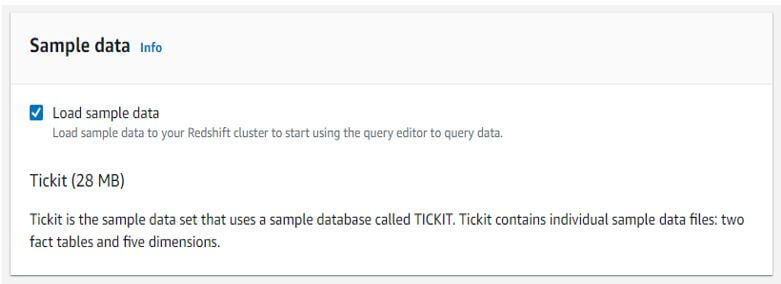
b. Configuring sample data for the cluster.
Sample data: Yes
Output:
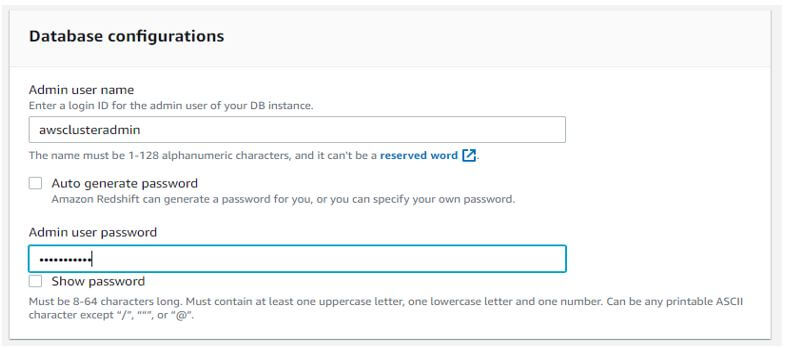
c. In database configuration we need to provide the user name and password.
Admin user name: awsclusteradmin
Admin user password: ***********
Output:
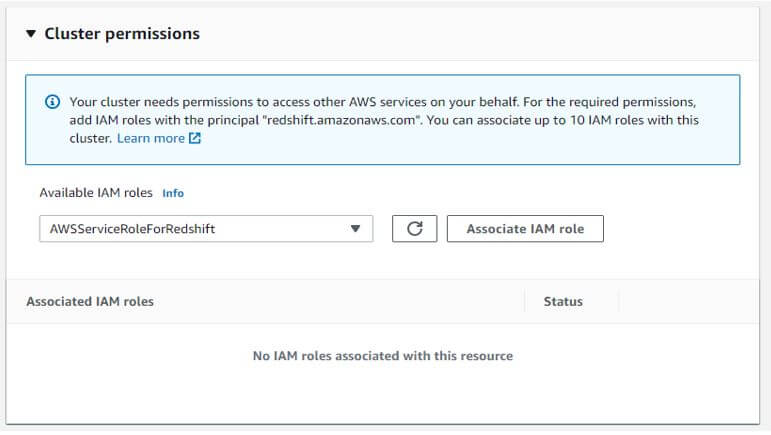
d. Configuring the cluster permission.
Available IAM roles: AWSServiceRoleForRedshift
Output:
e. Configuring the network and security option.
Virtual private cloud: default VPC
VPC security groups: default
Cluster subnet group: default
Availability zone: no preference
Enhanced VPC routing: disabled
Publicly accessible: disable
Output:
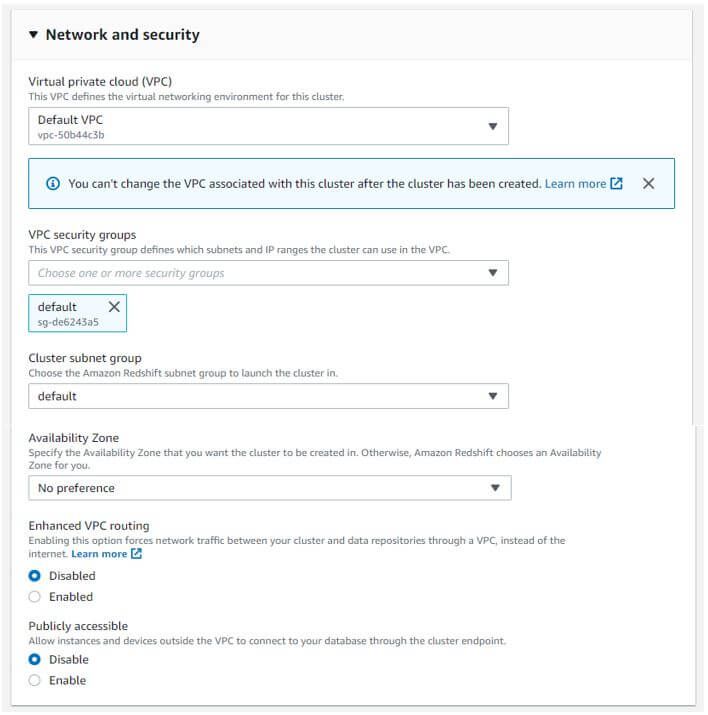
f. Configuring database details.
Database name: test
Database port: 5439
Parameter groups: default.redshift-1.0
Encryption: disabled
Output:
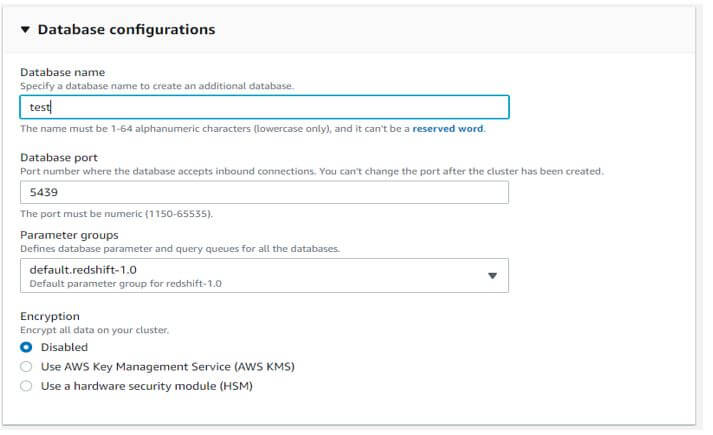
g. Configuring the maintenance window for the cluster.
Maintenance window: Monday 00:00 UTC+05:30
Maintenance track: current
Output:
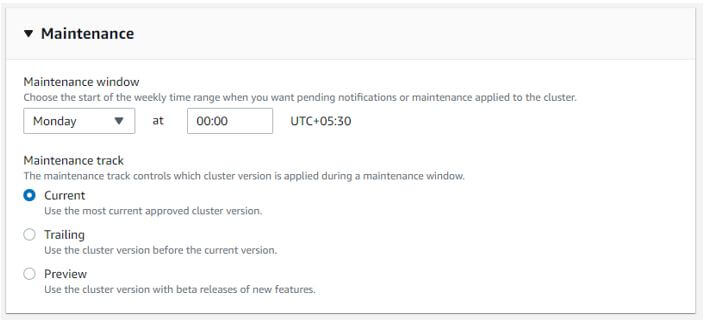
h. Configuring the backup.
Automated snapshot schedule: default schedule
Snapshot retention: 1 day
Configure – cross-region snapshot: disables
Cluster relocation: no
Output:
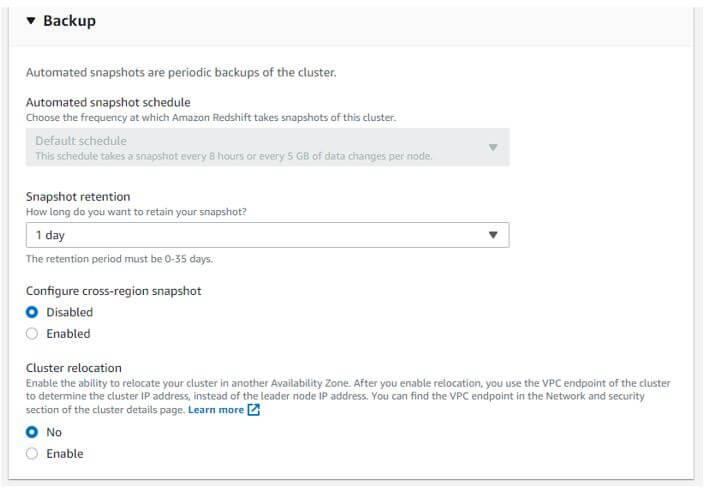
i. Create redshift cluster
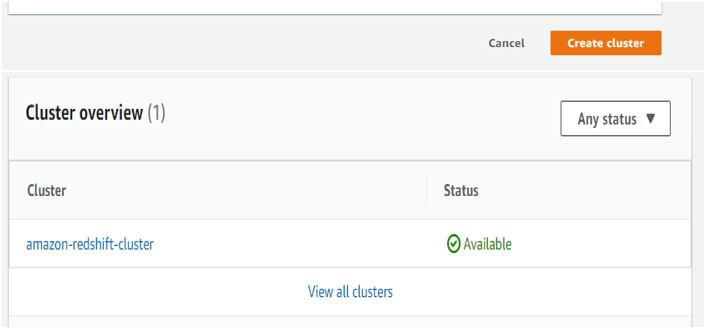
Example #2
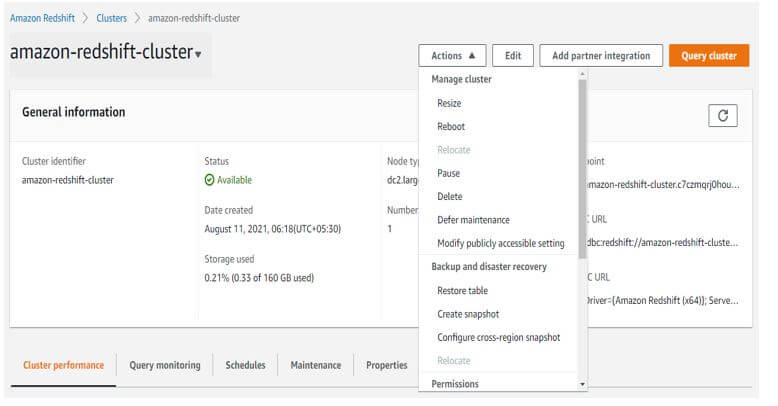
In the below example, we are rebooting the name as amazon-redshift-cluster.
Output:
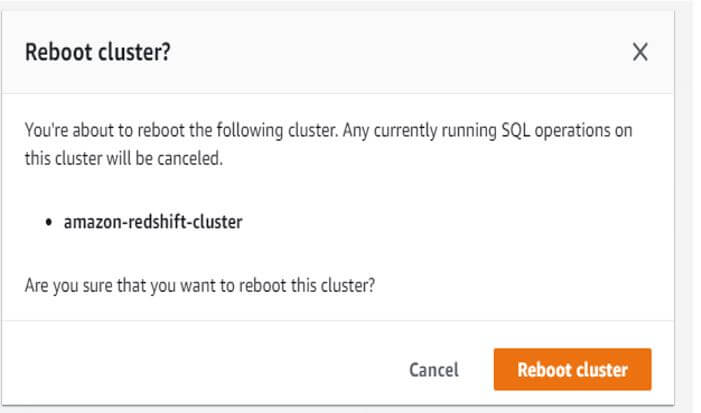
Example #3
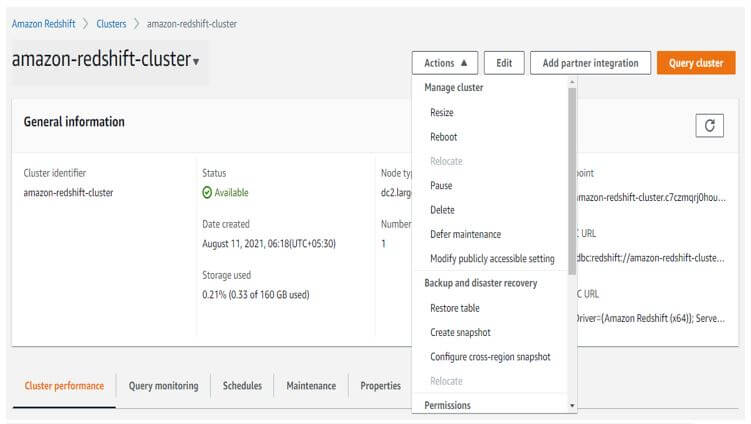
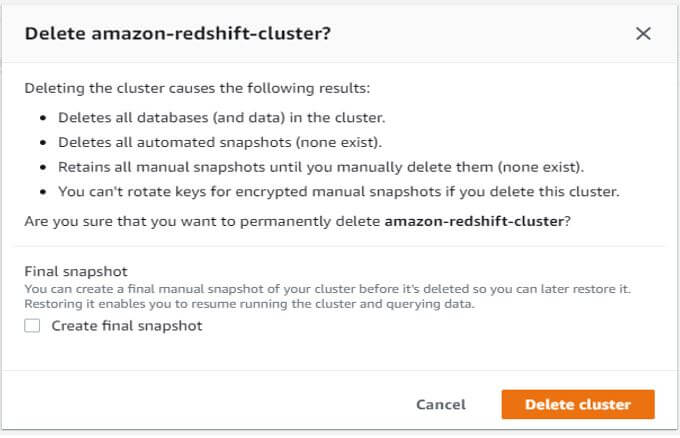
In the below example, we have to delete the name as amazon-redshift-cluster.
Output:
Conclusion
It is useful to execute the query faster. Leader and compute nodes are the two components available. After creating amazon we can optimize, resize and reboot and delete the cluster. We can create it using 2-128 node.
Recommended Articles
This is a guide to Redshift Cluster. Here we discuss the introduction, how cluster work in Redshift? and examples respectively. You may also have a look at the following articles to learn more –

