What is One-Hot Encoding?
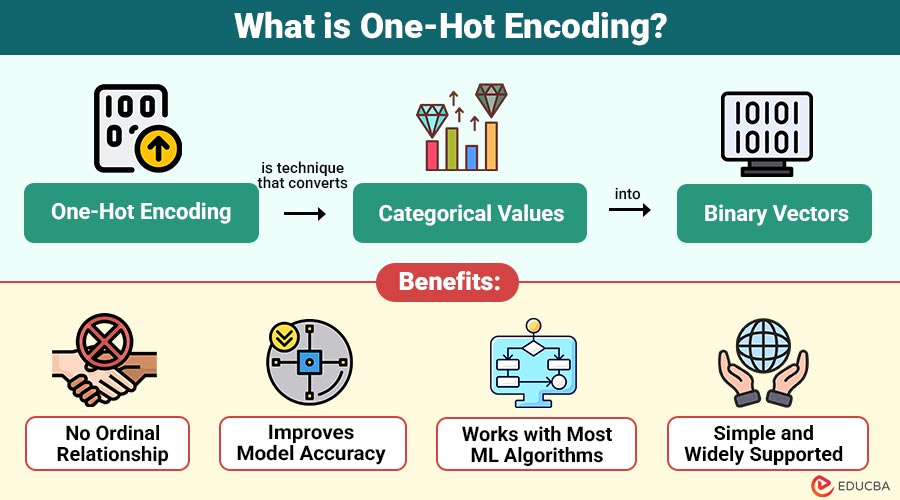
One-Hot Encoding is technique that converts categorical values into binary vectors. Each category is transformed into a separate column, and a value of 1 or 0 is assigned to indicate the presence or absence of that category.
Example:
Consider a column called “Color” with three categories:
- Red
- Blue
- Green
After one-hot encoding, it becomes:
| Color_Red | Color_Blue | Color_Green |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
This transformation ensures machine learning models can process categorical information effectively.
Table of Contents:
- Meaning
- Working
- Types
- When to Use One-Hot Encoding?
- When Not to Use One-Hot Encoding?
- Benefits
- Limitations
- Use Cases
Key Takeaways:
- One-Hot Encoding changes categorical variables into binary vectors, enabling machine learning models to interpret different categories accurately.
- It prevents models from learning spurious ordinal relationships and improves accuracy by representing categories independently, without bias.
- It increases dimensionality for high-cardinality features, making memory usage and computation significantly more expensive.
- Useful for nominal data and for algorithms that require numeric input, but unsuitable for ordered categories that require ordinal encoding.
How does One-Hot Encoding Work?
It follows a simple process:
Step 1: Identify Categorical Columns
These can be:
- Nominal (non-ordered): color, gender, country
- Binary: yes/no, male/female
- Multi-class: product category, city
Step 2: Create Separate Columns for each Category
Each unique value becomes a new column.
Step 3: Fill Rows with 1 or 0
- 1 → category present
- 0 → category absent
Conceptual Example:
If your dataset contains:
Animal:
- Dog
- Cat
- Horse
After encoding:
| Animal_Dog | Animal_Cat | Animal_Horse |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
Types of One-Hot Encoding
Here are the main types commonly used in machine learning and data processing:
1. Standard One-Hot Encoding
Creates separate binary columns for every category, representing presence or absence within categorical features.
2. One-Hot Encoding with Drop-First
Removes a categorical column to prevent multicollinearity, especially useful for regression-based machine learning models.
3. Sparse One-Hot Encoding
Stores only non-zero values, reducing memory usage when encoding extremely high-dimensional categorical datasets efficiently.
4. Hashing-Based One-Hot Encoding
Uses hashing to map categories into fixed-length vectors, which is effective for massive, high-cardinality feature spaces.
When to Use One-Hot Encoding?
Use One-Hot Encoding when dealing with:
1. Nominal (unordered) Categories
- Color
- Country
- Product name
- Vehicle type
2. Algorithms Requiring Numerical Input
- Logistic Regression
- Neural Networks
- Naive Bayes
- KNN
3. Small to Medium Number of Categories
Ideal when categories are manageable (e.g., < 50).
When Not to Use One-Hot Encoding?
One-Hot Encoding may not be suitable when:
1. High-Cardinality Columns
- City names (thousands)
- URLs (millions)
- Product IDs (hundreds of thousands)
It may create too many columns, leading to the curse of dimensionality.
2. When the Category has Natural Order
For ordinal variables like:
- Low, Medium, High
- Small, Medium, Large
Use ordinal encoding instead.
Benefits of One-Hot Encoding
Here are the key benefits of using it in machine learning and data processing:
1. No Ordinal Relationship
Prevents machine learning models from imposing any numerical order among categories, avoiding misleading comparisons such as “Blue > Red.”
2. Improves Model Accuracy
Helps models interpret categories independently, without unintended relationships, resulting in cleaner feature representations and improved predictive performance.
3. Works with Most ML Algorithms
Compatible with linear, tree-based, and neural network models, making categorical feature processing easier across diverse machine learning tasks.
4. Simple and Widely Supported
Easily implemented using popular libraries like Pandas, Scikit-learn, TensorFlow, and PyTorch, ensuring broad usability in projects.
Limitations of One-Hot Encoding
Here are the main limitations to consider when working with categorical data:
1. High Dimensionality
A feature with many distinct categories generates numerous columns, significantly increasing the dataset’s dimensionality and computational complexity.
2. Increased Memory Usage
Large binary matrices require substantial memory, making one-hot-encoded datasets expensive to store efficiently.
3. Sparse Data
Most encoded values are zero, resulting in sparse matrices that complicate storage, processing, and model training.
4. Difficult with Real-Time Systems
Maintaining consistent category mappings during live streaming data processing becomes challenging and prone to encoding mismatches.
Use Cases of One-Hot Encoding
Here are common use cases where it is effectively applied in machine learning and data processing:
1. E-commerce Personalization
Encodes product categories, colors, and brand attributes to personalize recommendations and enhance user-specific online shopping experiences.
2. Customer Segmentation
Transforms demographic attributes into numerical vectors, enabling clustering models to group customers based on behavioral patterns.
3. Natural Language Processing
Enables a range of natural language processing applications, such as text classification, by encoding characters or tokens for bag-of-words models.
4. Fraud Detection
Encodes transaction types, merchant categories, and customer groups to detect anomalous patterns indicative of fraudulent behavior.
5. Recommender Systems
Encodes user preferences, content genres, or ratings, allowing recommendation algorithms to generate personalized suggestions across items.
Final Thoughts
One-Hot Encoding is a foundational preprocessing method that converts categorical values into binary vectors, ensuring models interpret categories without implying order. Despite challenges with high-cardinality features, it remains effective and widely used across machine learning workflows. Applying it correctly improves model performance, reduces bias, and simplifies data preparation, making it an essential technique for handling categorical variables in most ML applications.
Frequently Asked Questions (FAQs)
Q1. Does One-Hot Encoding work for large categories?
Answer: Not recommended—use binary or target encoding instead.
Q2. Is one-hot encoding the same as dummy encoding?
Answer: Almost, except dummy encoding drops one column to avoid the dummy variable trap.
Q3. Can One-Hot Encoding be used for deep learning?
Answer: Yes, it is widely used in neural network preprocessing.
Q4. Is One-Hot Encoding reversible?
Answer: Yes—by mapping binary vectors back to category names.
Recommended Articles
We hope that this EDUCBA information on “One-Hot Encoding” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

