What is Multimodal AI?
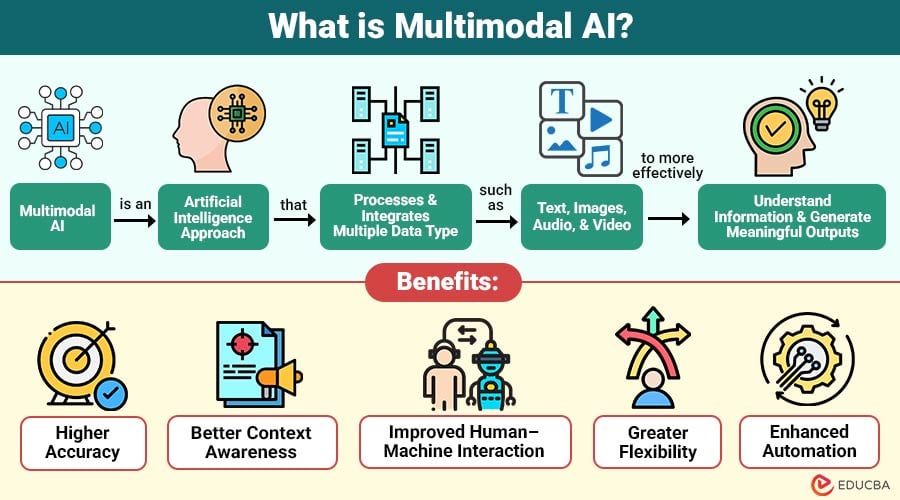
Multimodal AI is an artificial intelligence approach that processes and integrates multiple data types—such as text, images, audio, and video—to more effectively understand information and generate meaningful outputs.
Unlike traditional AI systems that rely on single data modality, multimodal AI combines various data sources to create a more comprehensive understanding of environment.
Example:
Consider a self-driving car. It relies on multiple data inputs, such as
- Camera images (visual data)
- Radar and LiDAR signals
- GPS location
- Sensor readings
By combining these inputs, the AI system can detect obstacles, recognize traffic signs, and navigate safely.
Table of Contents:
Key Takeaways:
- Multimodal AI combines text, images, audio, video, and sensor data to improve accuracy, context understanding, and intelligent decision-making.
- By integrating multiple data modalities, multimodal AI enables more natural human–machine interaction and effectively supports complex real-world problem-solving.
- Multimodal AI systems are strong, flexible, and incredibly effective thanks to cutting-edge technologies like deep learning, computer vision, and natural language processing.
- Multimodal AI improves automation by analyzing multiple data streams simultaneously, enabling faster decisions, higher productivity, and smarter business operations.
Why is Multimodal AI Important?
Below are the key reasons why multimodal AI is important in modern artificial intelligence systems.
1. Improved Accuracy
Combining multiple data sources allows AI systems to cross-verify information, reduce uncertainty, minimize errors, and make more reliable and precise decisions.
2. Better Context Understanding
Multimodal AI analyzes relationships among text, images, audio, and other inputs, enabling deeper contextual awareness and more meaningful interpretation of complex situations.
3. Enhanced User Experience
By understanding voice, text, and visual inputs together, multimodal AI creates more natural interactions, improving responsiveness, personalization, and overall user satisfaction in applications.
4. Real-World Problem Solving
Real-world settings involve diverse data, and multimodal AI enables systems to handle them simultaneously, yielding better insights in complex, evolving situations.
5. Advanced Automation
Organizations use multimodal AI to automate complex tasks by analyzing multiple data streams simultaneously, improving efficiency, productivity, and decision-making across various industries.
Types of Data Modalities in Multimodal AI
Multimodal AI systems process various types of data, known as modalities.
1. Text
Text modality includes written information such as documents, emails, chat messages, and social media posts that AI systems analyze for meaning.
2. Image
Image modality consists of visual data like photos, scanned files, diagrams, and medical images that AI models analyze to detect patterns, objects, or features.
3. Audio
The audio modality includes speech, music, and environmental sounds that AI systems process to accurately recognize words, emotions, tones, and other sound-based information.
4. Video
Video modality combines moving images and audio signals, allowing AI to understand actions, events, and behavior by analyzing sequences of frames over time.
5. Sensor Data
Sensor modality includes data collected from devices measuring temperature, motion, location, pressure, or biometric signals, helping AI understand physical environments and conditions.
How Does Multimodal AI Work?
Multimodal AI systems follow several stages to process different data types and produce insights.
1. Data Collection
Multimodal AI begins by collecting data from multiple sources, such as cameras, microphones, text files, databases, sensors, and user inputs for processing.
2. Data Preprocessing
Collected raw data is cleaned, formatted, and transformed into structured forms, such as resized images, tokenized text, and processed audio signals for modeling.
3. Feature Extraction
AI models analyze each modality separately to identify useful patterns such as image shapes, speech tones, keywords, emotions, and other meaningful characteristics in the data.
4. Data Fusion
Features from different modalities are combined using early, late, or hybrid fusion methods to create a unified representation for improved understanding.
5. Model Training
The fused data is used to train machine learning or deep learning models, enabling the system to learn relationships among multiple data types.
6. Decision or Output Generation
After training, the multimodal AI model generates predictions, classifications, or responses by analyzing combined inputs, providing accurate and context-aware results for users.
Key Technologies Behind Multimodal AI
Several advanced technologies support multimodal AI systems.
1. Deep Learning
Deep learning accurately analyzes complex patterns in text, photos, audio, and other data sources by using multi-layered neural networks.
2. Natural Language Processing
Natural language processing enables machines to understand, interpret, and generate human language from text or speech for meaningful communication and responses.
3. Computer Vision
Computer vision allows AI systems to analyze images and videos, detect objects, recognize faces, and understand visual scenes with high accuracy.
4. Speech Recognition
AI systems can comprehend voice commands and communicate with people through audio input thanks to speech recognition technology, which translates spoken words into text.
5. Data Fusion Techniques
Data fusion techniques combine information from different data modalities into a unified representation, improving accuracy, context understanding, and overall AI decision-making performance.
Real-World Examples of Multimodal AI
Several modern examples demonstrate the capabilities of multimodal AI.
1. Smart Assistants
Smart assistants use multimodal AI to understand voice commands, text inputs, and sometimes images, providing spoken, visual, or text-based responses to users.
2. Image Captioning Systems
Image captioning systems combine computer vision and language processing to analyze images and automatically generate accurate text descriptions explaining the visual content.
3. Medical Diagnostic Systems
Medical AI systems analyze medical images, patient history, and reports together, helping doctors detect diseases earlier and make more accurate treatment decisions.
4. AI Chatbots
Advanced AI chatbots process text messages, voice inputs, and images simultaneously, enabling more natural conversations, improved understanding, and more accurate responses for users.
Benefits of Multimodal AI
Multimodal AI offers several benefits compared to single-modality systems.
1. Higher Accuracy
Multimodal AI improves accuracy by combining multiple data sources, reducing uncertainty, minimizing errors, and producing more reliable predictions than single-modality systems.
2. Better Context Awareness
By analyzing relationships among text, images, audio, and other inputs, multimodal AI more clearly understands context and delivers more meaningful and relevant results.
3. Improved Human–Machine Interaction
Users can communicate with AI using voice, text, and images, enabling more natural interaction, better understanding, and improved overall user experience.
4. Greater Flexibility
Multimodal AI systems work effectively in complex, heterogeneous environments, enabling better adaptability across diverse real-world situations.
5. Enhanced Automation
Organizations use multimodal AI to automate complex processes by analyzing multiple data streams together, increasing efficiency, productivity, and accuracy in operations.
Challenges of Multimodal AI
Despite its benefits, implementing multimodal AI can be complex.
1. Data Integration Complexity
Integrating text, images, audio, and sensor data requires advanced architectures, complex algorithms, and careful synchronization to ensure accurate and meaningful combined analysis.
2. High Computational Cost
Multimodal AI models must analyze multiple data types simultaneously during training and execution; they require powerful hardware, large memory, and high processing capacity.
3. Data Alignment Issues
Different modalities may differ in timing, format, or context, making it difficult to align data correctly for accurate interpretation and model training.
4. Limited Training Data
Training multimodal AI models, which require large, diverse, and well-labeled data sources, becomes challenging due to the limited availability of high-quality datasets containing multiple modalities.
5. Privacy Concerns
Using multiple data sources, such as audio, video, and personal information, increases privacy risks and requires strong security measures and ethical guidelines for safe use.
Final Thoughts
Multimodal AI is advanced form of artificial intelligence that integrates text, images, audio, video, and sensor data to improve understanding and decision-making. It is widely used in healthcare, autonomous vehicles, virtual assistants, and business automation. Despite challenges such as high computational cost, continuous advancements are making multimodal AI more efficient, enabling smarter, more adaptive intelligent systems.
Frequently Asked Questions (FAQs)
Q1. What is the main purpose of multimodal AI?
Answer: The main purpose of multimodal AI is to combine multiple types of data to improve understanding and decision-making.
Q2. Can multimodal AI work in real-time applications?
Answer: Yes, multimodal AI can work in real-time applications such as smart assistants, autonomous vehicles, and security systems, but it requires powerful hardware and optimized algorithms for rapid processing.
Q3. Where is multimodal AI commonly used?
Answer: It is widely used in healthcare, autonomous vehicles, virtual assistants, security systems, and e-commerce platforms.
Recommended Articles
We hope that this EDUCBA information on “Multimodal AI” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

