Updated March 15, 2023
Introduction to Keras Metrics
We need certain functions known as Keras’ metrics to judge and measure the model performance we created in Keras. Loss functions and metric functions are quite similar in nature and behavior. The only difference between them is that the loss function involves the usage of the generated results in the model training process. In contrast, metric functions do not use the resultant for training the model.
This article will lighten Keras metrics and cover the related points, including Keras metrics, how to create Keras metrics, Keras metrics classification, Keras metrics customization, and a conclusion about the same.
What are Keras metrics?
Metrics are the functions used in keras to measure the model’s performance. The loss and metric functions are similar, having only the difference in usage of results for the training process. In loss functions, the resultant generated is used in the training process, while metric functions don’t follow this approach. We can even use the loss function as the metric for performance analysis. There are many available functions that you can use as metrics. However, you are also free to create your customized metric functions.
How to create keras metrics?
We can create a customized metric by following either of two approaches. One is by using simple callable, which are stateless, that means does not store information about the state. The other way is by treating it as the subclass of the Metric class, which is a stateful process as the information of the instance is maintained in the state.
We will be seeing both of these methods in the below section of the customized metric creation section.
Keras metrics classification
Metrics are classified into various domains that are created as per the usage. This section will list all of the available metrics and their classifications –
1. Probabilistic Metrics
- KL Divergence class
- Binary Cross entropy class
- Sparse categorical cross-entropy class
- Poisson class
- Categorical cross-entropy class
2. Accuracy Metrics
- Binary accuracy class
- Sparse categorical accuracy class
- Accuracy class
- Sparse top k categorical accuracy class
- Top k categorical accuracy class
- Categorical accuracy class
3. Classification metrics based on negative and positive Boolean values and true and false.
- Sensitivity at specificity class
- Recall class
- Precision class
- AUC class
- True negative class
- True positives class
- False negatives class
- False positives class
- Specificity in sensitivity class
- Precision at recall class
4. Regression metrics
- Cosine similarity class
- Mean absolute percentage error class
- Mean squared error class
- Mean absolute error class
- Root mean squared error class
- Log cosh error class
- Mean squared logarithm error class
5. Hinge metrics for maximum margin classification
- Squared hinge class
- Hinge class
- Categorical hinge class
6. Image segmentation metrics
- Mean IO U class
Keras metrics Customize
The stateless method as simple callables –
This process is similar to that of the loss function, where the callable will have the specified signature as a metric function (y true, y prediction) and which results in the output returning the value in the array of the loss(es) so that it can be further transferred to the compile() function as a metric value. The array of losses will be a sample of the batch of input values. When we follow this process, the support for sample weighting is provided automatically internally.
Let us consider an example –
Axis value will be kept as -1 in this example –
def sampleEducbaMetricFunction(trueYValue, predictionY):
calculatedDifferenceOfSquare = tf.square(trueYValue - predictionY)
return tf.reduce_mean(calculatedDifferenceOfSquare, axis=-1)
model.compile(optimizer='adam', loss='mean_squared_error', metrics=[sampleEducbaMetricFunction])
print ("Compiled successfully by using the specified metrics.")
After execution of the above code snippet, you get the following output –
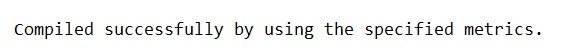
For the above example, to track the records while training and evaluating the scalar metrics, we are using the value calculated of an average of metric values per batch for all the given batches for the call given to the model. evaluate() function or all the given epochs.
Stateful method of treating it as a subclass of the Metric class –
It is impossible to represent all the metrics as the callables in stateless form. This is because the metrics are being evaluated for each batch of evaluation and training. But there are some scenarios where we are not interested in the average values per batch.
Let us consider one scenario where we want the computation of AUC preferred more than that of the data evaluation for the input. This means that the average of AUC’s value per batch is not the same as that of the value of AUC for the entire set of data.
For this kind of metric, we will be subclassing the class named Metric to ensure that the state is being maintained for all the batches. For this, we will follow the below-mentioned steps –
• _init_ will be used for the creation of state variables
• Update_state() function will contain the code related to the updation of y prediction and y true values.
• Result() function will return the value of the metric of scalar form.
• We can then clear all the states by using the method function reset_states()
Let us consider one example for this implementation –
class booleanValueOfTruePositives(tf.keras.metrics.Metric):
def __init__(self, name='binartrueValueOfY_positives', **kwargs):
super(booleanValueOfTruePositives, self).__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name='tp', initializer='zeros')
def update_state(self, trueValueOfY, predictionValueY, testWeightValue=None):
trueValueOfY = tf.cast(trueValueOfY, tf.bool)
predictionValueY = tf.cast(predictionValueY, tf.bool)
sampleValuesForEvaluation = tf.logical_and(tf.equal(trueValueOfY, True), tf.equal(predictionValueY, True))
sampleValuesForEvaluation = tf.cast(sampleValuesForEvaluation, self.dtype)
if testWeightValue is not None:
testWeightValue = tf.cast(testWeightValue, self.dtype)
sampleValuesForEvaluation = tf.multiply(sampleValuesForEvaluation, testWeightValue)
self.true_positives.assign_add(tf.reduce_sum(sampleValuesForEvaluation))
def result(self):
return self.true_positives
def reset_states(self):
self.true_positives.assign(0)
sampleObj = booleanValueOfTruePositives()
sampleObj .update_state([0, 1, 1, 1], [0, 1, 0, 0])
print('Result in between the process:', float(sampleObj .result()))
m.update_state([1, 1, 1, 1], [0, 1, 1, 0])
print('The last acquired result:', float(sampleObj .result()))
The execution of the above code snippet results into –

Conclusion
We can create the Keras metrics according to our necessities by customizing them or using them from the classes available to evaluate our Keras model’s performance.
Recommended Articles
This is a guide to Keras Metrics. Here we discuss the Introduction: What are Keras metrics, and how to create keras metrics?. You may also look at the following articles to learn more –
