Updated March 14, 2023

Definition of Keras LSTM Example
LSTM in neural network stands for Long short-term memory which is an artificial recurrent neural network that is basically used in deep learning or machine learning. In general, a normal neural network follows the concept of feedforward neural network which takes in single input and gives out the output from the traversal within hidden layers. LSTM network gels very well with the networks that do processing, classifying, and predictions based on time series which are mostly applicable to applications related to unsegmented, speech recognition, and detection with network traffic in and around of every network.
How to use keras LSTM Example?
In general, neural network works in a fashion where the network flows with the concept of feedforward where the input data provided to the network flows and travels in only one direction within the hidden layer expecting some output to the output layer. Whereas lstm network also known as RNN (Recurrent neural network) is a bit critical concept as it involves traversal of data in cycles format via different layers.
In other words, keras lstm with RNN neural network leverages the facility and ability to compare sequential data dynamically to store the stuff that has been predicted.
In keras lstm why RNN is used?
As mentioned above simple neural network just works with the concept of feed forward neural network whereas RNN can judge in a way where the new datasets will rely on information from previous data which in turn will help in the prediction of data when dealing with sequential data. Also, RNN as its name suggest possesses a separate layer to store the output for any input and is thus abbreviated as recurrent.
Let’s dive into the flow of use of keras lstm example:
Since RNN has the capability to remember the characteristics of its previous input and set of previous output but the question arises with the fact that how long can it remember and predict what information is about to come or create some influence over the existing network?
For example: While writing a phrase in a paragraph a sentence is phrased with the set of words like I am an Indian and I am proud to be an Indian. Now the ask is to identify easily the first letter written in Bold and then that recurrent neural network should be able to identify the input and its respective output.
But when the RNN tries to identify the first Bold within the sentence like I it easily identifies, processing starts, and then classification too happens but when it comes to the identification of the next capital letter I then with respect to that the processing and classification take time which is known as the problem of long-term dependency. So basically, there is a four-layer neural network that exists in RNN that deals with this problem of long-term dependency.
The core ideas behind designing an LSTM is as follows:
- A cell state is a type of state where it acts as a conveyor belt that flows in and out the entire chain with some linear interactions in-between.
- These LSTM networks do have the capability to add or remove these cell states accordingly which gets regulated by other structures known as gates.
- Gates are the optional way to make the information flow through which consists of many layers like the sigmoid layer for making the manipulation between digits like zero and one.
- Each layer is associated with one or the other layer accordingly for manipulation and other formalities to work with.
So, with this implementation of keras LSTM can be done with the help of certain libraries, LSTM network, and some of the MNIST dataset that includes handwritten data like words and sentences for filtering and mapping.
Implementation Details:
Some of the modules that will be needed to import for manipulation are as follows:
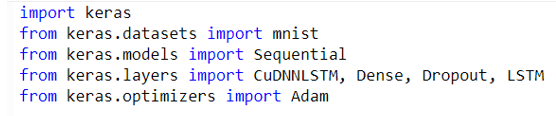
Once all these necessary modules from the library are loaded next step is to get the MNIST dataset loaded within it so that the filters can be made accordingly therefore the next step is to import and preprocess MNIST data:

Once the required data is loaded using MNIST the next step is to create a customized LSTM network:
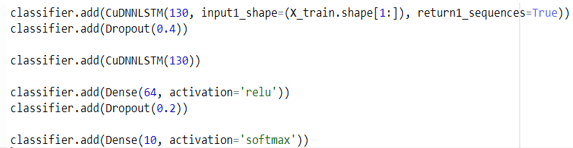
- Initialize a necessary classifier Network
![]()
- Add input to the LSTM network layer accordingly
![]()
Note: significance of return1_sequences is set to true which means that the outflow of the sequence will return some output to the next layer. Therefore, if it is set to false then it will not generate any sequence for its other flow.
- A second LSTM network is added, followed by a dense hidden layer and adding the output layer accordingly.
- If there is no need for any GPU or GPU usage is not required, then in that case there is no need to use anything rather CUDA framework can be used only.
- The next step is to compile the LSTM network and verify if the data is fitting properly or not.

- Verification of the output can be done based on the Accuracy and set the test case accordingly.
- This designed model can be used wherever the requirement is to change the state from its preceding state based on information. So, if there is a change in a word with its sentence then it will be requiring some more sophisticated ways or methods to capture the interplay between words which is not that good.
- Even hyperparameters and other parameters need to be customized according to the network requirement.
- As computers don’t understand words, they just understand sentences therefore to frame them it is required to use the tokenizer for parsing and composing the phrases accordingly.
- If the data sets and the testing set have some discrepancies, then in that case it becomes very tough to manipulate.
Conclusion
Keras lstm is a good option to explore when the requirement comes with deep learning applications where the prediction needs accuracy. As the networks possess certain complex layers for the flow of data it requires certain flow accordingly which has to be very prominent in terms of the preceding stage and successive stage.
Recommended Articles
This is a guide to Keras LSTM Example. Here we discuss the Introduction, How to use keras LSTM Example, why RNN is used, types. You may also have a look at the following articles to learn more –
