Updated March 15, 2023
Introduction to Keras Batch Normalization
Keras batch normalization is the layer in Keras responsible for making the input values normalized, which in the case of batch normalization brings the transformation, making it possible to keep the value of the standard deviation near one and mean output near 0. In this article, we will dive into Keras batch normalization. First, we will try to understand it by having the subtopics of What is Keras batch normalization, How to use Keras batch normalization, How to create and configure, keras batch normalization example, and Conclusion about the same.
What is Keras batch normalization?
Keras batch normalization is the layer whose class is provided where we can pass required parameters and arguments to justify the function’s behavior, which makes the input values to the Keras model normalized. Normalization brings the standard deviation for the output near the value of 1 while the mean output comes near 0. The behavior and application of batch normalization differ in the interface and training process.
How to use keras batch normalization?
Keras batch normalization layer has its class definition as given below –
Tensorflow.keras.layers.BatchNormalization(axis=-1,
momentum=0.99,
beta_initializer="zeros",
moving_variance_initializer="ones",
beta_constraint=None,
moving_mean_initializer="zeros",
beta_regularizer=None,
scale=True,
gamma_constraint=None,
epsilon=0.001,
center=True,
gamma_initializer="ones",
gamma_regularizer=None,
**kwargs)
The arguments used in the above definition are described in brief –
• Axis: It is an integer value that specifies that the feature axis or the other ones should also be normalized.
• momentum: It is the value of momentum associated with the moving average.
• epsilon: To avoid the divide by zero error scenario, a small value that is epsilon is added to the value of variance.
• center: When this value is set to false the beta is completely ignored, and when set to true for normalizing the tensor value, the offset is added to the beta value.
• scale: When this value is set to false the gamma is ignored, and when set to true, the multiplication with gamma is carried out.
• beta_initializer: Assign the initial value to the weight of beta.
• gamma_initializer: gamma weight is assigned the initial value.
• moving_mean_initializer: Moving means is assigned with the initial value.
• moving_variance_initializer: Moving variance is assigned with the initial value.
• beta_regularizer: It is an optional argument that regularizes the beta weight.
• gamma_regularizer: It is an optional argument that regularizes the gamma weight.
• beta_constraint: It is an optional argument that acts as a constraint for the beta weight.
• gamma_constraint: It is an optional argument that acts as a constraint for the gamma weight.
• Input value: It can be a tensor input having any value of rank.
• Training: This is a crucial parameter specifying a Boolean value for specifying whether the model should work in inference or training mode which has its value training = true or training = false.
• Input shape: It is an arbitrary value which is an integer tuple for dimension and size specification
• Output shape: It has the same value as the input shape.
How to create and configure?
When we are making the use of the fit() function while training the model or while the model or layer is being called along with the argument value specification of training = true, input values of the current batch are used for normalizing the outputs by the layer with the help of standard deviation and mean values of inputs. The value returned by the layer for each of the channels that it normalizes is equivalent to –
gamma * (batch – mean(batch)) / sqrt(var(batch)+ epsilon) +beta
In the above output formula –
- The epsilon value is a small configurable constant passed as an argument to the constructor.
- The value of gamma is set to 1 in the initial stage and is the learned scaling factor. It is disabled when we pass the value scale = false in the layer’s constructor.
- The value of beta is by default initialized to 0 and is the value of the learned offset factor. This value can be disabled by setting the center = false in the layer’s constructor.
When the layer is used in the inference, that is when the value of argument training = false is passed in the constructor of the layer, which is the default value of the training argument, or we give a call to the functions of predict () and evaluate () the layer behaves in inference way. In this, the outputs are normalized by the layer with the help of moving average of standard deviation and mean for all the batches the model sees during the training process. The value returned by the layer is equivalent to this –
Gamma * (batch – self.moving_mean) / sqrt (self.moving_var +epsilon) + beta
While in the training mode, each ti,e the layer is being called the value of the non-trainable variables, namely self.moving_var and self.moving_mean are updated, which takes the following formula for calculation –
Moving_var = moving_var * momentum + var (batch) * (1- momentum)
Moving_mean = moving_mean * momentum + mean (batch) * (1- momentum)
During inference, If the trained data is quite similar to the inference data in the statistics, then only the layer controls input values.
keras batch normalization example
given below are the example of Keras Batch Normalization:
from extra_keras_datasets import kmnist
import tensorflow
from tensorflow.keras.sampleEducbaModels import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import BatchNormalization
# set the configurations of the sampleEducbaModel
sizeOfBatch = 250
countOfEpochs = 25
countOfClasses = 10
splitForValidation = 0.2
valueOfVerbose = 1
# kmnist data should be loaded
(trainingInput, trainingTarget), (testingInput, testingTarget) = kmnist.load_data(type='kmnist')
# define the input shape of the sets
trainingInput_shape = trainingInput.shape
testingInput_shape = testingInput.shape
# Keras layer input shape
shapeOfInput = (trainingInput_shape[1], trainingInput_shape[2], 1)
# In order to add channels, reshape the data of input
trainingInput = trainingInput.reshape(trainingInput_shape[0], trainingInput_shape[1], trainingInput_shape[2], 1)
testingInput = testingInput.reshape(testingInput_shape[0], testingInput_shape[1], testingInput_shape[2], 1)
# numbers should be parsed as float values
trainingInput = trainingInput.astype('float32')
testingInput = testingInput.astype('float32')
# Input data should be normalized
trainingInput = trainingInput / 255
testingInput = testingInput / 255
# Sequential keras Model Creation
sampleEducbaModel = Sequential()
sampleEducbaModel.add(Conv2D(32, kernel_size=(3, 3), activation='relu', shapeOfInput=shapeOfInput))
sampleEducbaModel.add(BatchNormalization())
sampleEducbaModel.add(MaxPooling2D(pool_size=(2, 2)))
sampleEducbaModel.add(BatchNormalization())
sampleEducbaModel.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
sampleEducbaModel.add(BatchNormalization())
sampleEducbaModel.add(MaxPooling2D(pool_size=(2, 2)))
sampleEducbaModel.add(BatchNormalization())
sampleEducbaModel.add(Flatten())
sampleEducbaModel.add(Dense(256, activation='relu'))
sampleEducbaModel.add(BatchNormalization())
sampleEducbaModel.add(Dense(countOfClasses, activation='softmax'))
# Model compilation
sampleEducbaModel.compile(loss=tensorflow.keras.losses.sparse_categorical_crossentropy,
optimizer=tensorflow.keras.optimizers.Adam(),
metrics=['accuracy'])
# The data should eb fitted to the sampleEducbaModel
history = sampleEducbaModel.fit(trainingInput, trainingTarget,
sizeOfBatch=sizeOfBatch,
epochs=countOfEpochs,
verbose=valueOfVerbose,
splitForValidation=splitForValidation)
# generalized metrics should be generated
achievedScore = sampleEducbaModel.evaluate(testingInput, testingTarget, verbose=0)
print(f'Loss of Test - {achievedScore[0]} / Accuracy of Test - {achievedScore[1]}')
The execution of the above code snippet with additional code files gives the following output –
![]()
In terms of graphs, the output is –
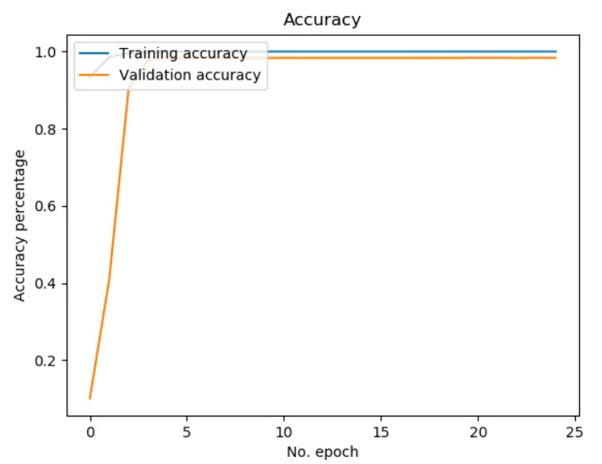
And for loss –
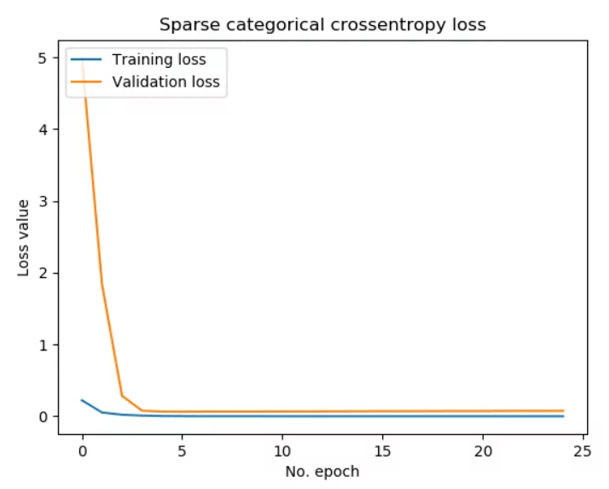
Conclusion
Keras batch normalization is the layer of keras that brings the standard deviation for the output near the value of 1 while the mean output comes near 0, making the input normalized.
Recommended Articles
This is a guide to Keras Batch Normalization. Here we discuss the Introduction, What is Keras batch normalization, and How to create and configure it?. You may also look at the following articles to learn more –
