What is Data Sharding?
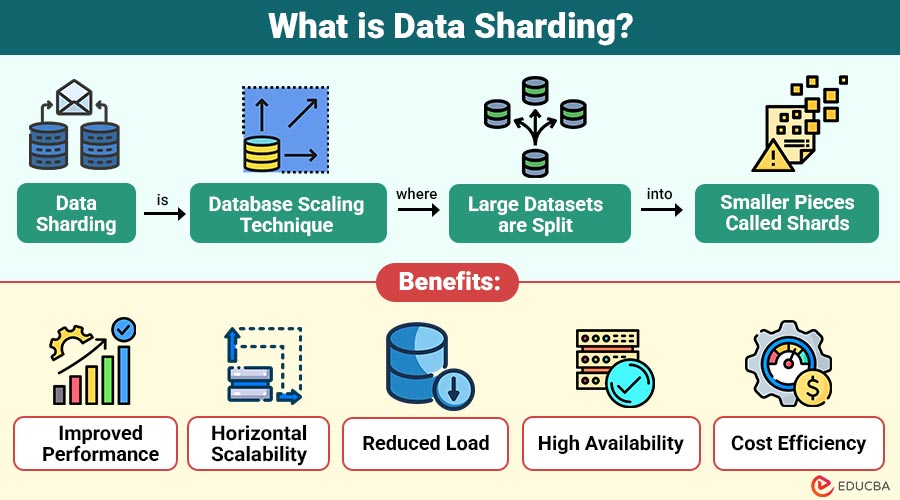
Data Sharding is a database scaling technique where large datasets are split into smaller pieces called “shards.” These shards are stored across multiple machines to improve performance, availability, and manageability.
Instead of placing all data in a single database server, sharding distributes it across multiple servers, each holding a subset of the data. Every shard functions independently yet remains part of a unified system.
Table of Contents:
- Meaning
- Why does Data Sharding Matter?
- Working
- Types
- Benefits
- Challenges
- Real-World Examples
- Differences
Key Takeaways:
- Data sharding enables distributed data storage across servers, improving application speed as datasets grow rapidly.
- It provides a scalable architecture by allowing systems to expand horizontally without costly hardware upgrades.
- It optimizes query processing by routing requests to specific shards rather than scanning entire databases.
- It improves global application performance by storing region-specific data closer to users, reducing latency.
Why does Data Sharding Matter?
Here are the key reasons data sharding matters as applications grow and workloads increase.
1. Slow Queries from Large Tables
Large table sizes significantly increase query execution time, reducing overall application performance.
2. Heavy Load on a Single Server
Concentrating all database operations on one server results in a heavy load, reducing system responsiveness.
3. Costly Vertical Scaling
Upgrading hardware components such as RAM and the CPU becomes increasingly costly and eventually reaches physical performance limits.
4. Limited Storage Capacity
A single database server eventually runs out of available storage, limiting further data growth.
5. Lower System Availability
When a server becomes overloaded, the entire application becomes unavailable, causing severe downtime and user dissatisfaction.
How does Data Sharding Work?
Data sharding works by splitting a large dataset into smaller, manageable parts stored across multiple servers for faster and more efficient processing.
1. Shard Keys
A shard key is a field used to determine where data is stored.
Examples:
user_id, customer_id, region, order_id
2. Shards
These are the actual database partitions distributed across multiple servers.
3. Routing Layer (Query Router)
This layer identifies which shard holds the required data. Systems like MongoDB use the mongos router, while MySQL uses proxy-based routers.
Workflow:
- The client sends a query
- The router checks the shard key
- The request goes to the correct shard
- Shard processes and returns the result
This modeling ensures efficient querying without scanning the entire database.
Types of Data Sharding
Here are the different types of data sharding used to distribute and scale large datasets efficiently.
1. Horizontal Sharding (Row-Based Sharding)
Data is distributed across multiple servers by partitioning rows, enabling efficient scaling for very large datasets.
Example:
- Shard 1 contains users with IDs 1–1,000,000
- Shard 2 contains users with IDs 1,000,001–2,000,000
2. Vertical Sharding (Column-Based Sharding)
Data is partitioned by column across multiple servers, improving performance when application components use distinct fields.
Example:
- Shard 1: user profile data
- Shard 2: user authentication data
3. Directory-Based Sharding
A central lookup table tracks which shard stores specific records, enabling flexible data movement and dynamic distribution.
Example:
| User ID | Shard |
| 1–1M | Shard A |
| 1M–2M | Shard B |
4. Range-Based Sharding
Data is partitioned into shards based on continuous key ranges, which is ideal for sorted data such as dates or identifiers.
Example: orders by date range.
5. Geo-Based Sharding
Data is distributed to region-specific servers according to user location, improving latency and performance for global systems.
Example:
- North America → Shard A
- Europe → Shard B
Benefits of Data Sharding
Here are the major benefits that make data sharding essential for scaling modern databases.
1. Improved Performance
Each shard contains smaller datasets, enabling faster query execution and reducing overall database response time.
2. Horizontal Scalability
Systems can scale easily by adding additional servers, eliminating the need for expensive vertical hardware upgrades.
3. Reduced Load
Data and traffic are distributed evenly across shards, preventing excessive stress on any single database server.
4. High Availability
Failure of one shard does not impact the entire system, ensuring continuous application functionality and uptime.
5. Cost Efficiency
Multiple inexpensive servers replace a single powerful machine, significantly reducing infrastructure costs while maintaining performance.
Challenges of Data Sharding
Here are the key challenges organizations face when implementing and managing data sharding.
1. Complex Architecture
Managing distributed shards demands advanced engineering, increasing system complexity, and requiring specialized operational expertise.
2. Rebalancing Difficulty
Redistributing data across new shards during scaling operations is challenging, time-consuming, and error-prone.
3. Cross-Shard Queries
Queries involving multiple shards slow down significantly because data must be fetched and aggregated across servers.
4. Data Consistency Issues
Maintaining strong consistency across shards requires strict coordination, which adds substantial overhead and complicates system reliability.
5. Application-Level Logic
Applications often require additional routing logic to determine appropriate shards, increasing development effort and complexity.
Real-World Examples
Here are some well-known real-world systems that use data sharding to operate at a massive scale.
1. Facebook
Uses user-ID-based sharding, with each shard handling a subset of user profiles and posts.
2. Twitter
Shards tweets by user ID and follows a snowflake ID structure for scalable handling of tweet data.
3. Google Cloud Spanner
Uses automated sharding and rebalancing to support global-scale applications.
Difference Between Sharding and Partitioning
Here is a clear comparison of sharding and traditional database partitioning.
| Feature | Sharding | Partitioning |
| Definition | Distributing data across multiple servers | Dividing data within one server |
| Scale | Horizontal | Vertical |
| Purpose | Handle massive scale | Improve internal performance |
| Hardware | Multiple instances | Single machine |
| Use Case | Global applications | Medium-scale optimization |
Final Thoughts
Data sharding is a powerful scaling technique that splits large datasets into smaller shards across multiple servers, boosting performance, availability, and scalability. Though it adds architectural complexity, it becomes essential as applications outgrow single-server limits. For high-traffic apps, e-commerce platforms, social networks, or global SaaS systems, sharding ensures long-term speed, reliability, and growth readiness.
Frequently Asked Questions (FAQs)
Q1. Does sharding affect database consistency?
Answer: Yes, distributed systems require careful handling of consistency models, such as eventual consistency.
Q2. Is sharding suitable for small applications?
Answer: Not necessary. Small systems can scale vertically; sharding is best when data grows beyond a single machine.
Q3. Does sharding increase system complexity?
Answer: Yes. It requires routing logic, monitoring, balancing, and distributed transaction handling.
Q4. Which databases support sharding?
Answer: MySQL, MongoDB, Cassandra, PostgreSQL (via Citus), Elasticsearch, HBase, Couchbase, Vitess.
Recommended Articles
We hope that this EDUCBA information on “Data Sharding” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

