Updated September 28, 2023

Differences Between Data Scientist vs Machine Learning Engineer
A Data Scientist is an expert responsible for collecting, examining, and interpreting large volumes of data to recognize ways to help a business improve operations and gain a viable edge over rivals. It follows an interdisciplinary approach. It lies between the connection of math, Statistics, Software Engineering, Artificial Intelligence, and Design Thinking. It deals with data collection, cleaning, analysis, visualization, validation model, experiments prediction, designing, testing, and hypothesis many further. Machine learning is a division of artificial intelligence data science utilized to attain its objectives. Machine Learning mainly focuses on algorithms, polynomial structures, and word adding. It consists of algorithms and machines, enabling them to learn without being programmed.
Data Scientist
This Data Scientist role is a branch of the statistics part, which includes using advanced analytics technologies, including machine learning and predictive modeling, to provide visions beyond statistical analysis. The petition for data science skills has grown significantly in recent years as companies look to collect helpful information from the huge amounts of structured, semi-structured, and unstructured data that a large enterprise produces and is collectively referred to as big data. The goal of all the steps is to derive insights from data.
Standard tasks:
- Allocate, aggregate, and synthesize data from various structured and unstructured sources.
- Explore, develop, and apply intelligent learning to real-world data and provide essential findings and successful actions based on them.
- Analyze and provide data collected in the organization.
- Design and build new processes for modeling, data mining, and implementation.
- Develop prototypes, algorithms, predictive models, and prototypes.
- Carry out requests for data analysis and communicate their findings and decisions.
In addition, there are more specific tasks depending on the domain in which the employer works or the project is being implemented.
Raw Data —> Data Science —-> Actionable Insights
Machine Learning Engineer
The Machine Learning Engineer position is more “technical.” ML Engineer has more in common with classical Software Engineering than Data Scientists. It helps you learn the objective function, which plots the inputs to the target variable and independent variables to the dependent variables.
The standard tasks of ML Engineers are generally like Data scientists. You also need to be able to work with data, experiment with various Machine Learning algorithms that will solve the task, and create prototypes and ready-made solutions.
The required knowledge and skills for this position also overlap with Data scientists. Of the key differences, I would single out the following:
- Strong programming skills in one or more popular languages (usually Python and Java) and databases.
- Less emphasis on the ability to work in data analysis environments but more emphasis on Machine Learning algorithms.
- R and Python for modeling are preferable to Matlab, SPSS, and SAS.
- Ability to use ready-made libraries for various stacks in the application, for example, Mahout, Lucene for Java, and NumPy / SciPy for Python.
- Ability to create distributed applications using Hadoop and other solutions.
As you can see, the position of ML Engineer (or narrower) requires more knowledge in Software Engineering and, accordingly, is well suited for experienced developers. The case often works when the usual developer must solve the ML task for his duty, and he starts to understand the necessary algorithms and libraries.
Head-to-Head Comparison Between (Infographics)
Below are the top 5 differences between Data scientists and Machine Learning Engineer:
Key Difference Between Data Scientist and Machine Learning Engineer
Below are the lists of points that describe the key Differences Between Data Scientist and Machine Learning:
- Machine learning and statistics are part of data science. The word learning in machine learning means that the algorithms depend on data used as a training set to fine-tune some model or algorithm parameters. This encompasses many techniques, such as regression, naive Bayes, or supervised clustering. But not all styles fit in this category. For instance, unsupervised clustering – a statistical and data science technique – aims at detecting clusters and cluster structures without any prior knowledge or training set to help the classification algorithm. A human being is needed to label the clusters found. Some techniques are hybrid, such as semi-supervised classification. Some pattern detection or density estimation techniques fit into this category.
- Data science is much more than machine learning, though. Data in data science may or may not come from a machine or mechanical process (survey data could be manually collected, and clinical trials involve a specific type of small data), and it might have nothing to do with learning, as I have just discussed. But the main difference is that data science covers the whole spectrum of data processing, not just the algorithmic or statistical aspects. Data science also covers data integration, distributed architecture, automated machine learning, data visualization, dashboards, and Big data engineering.
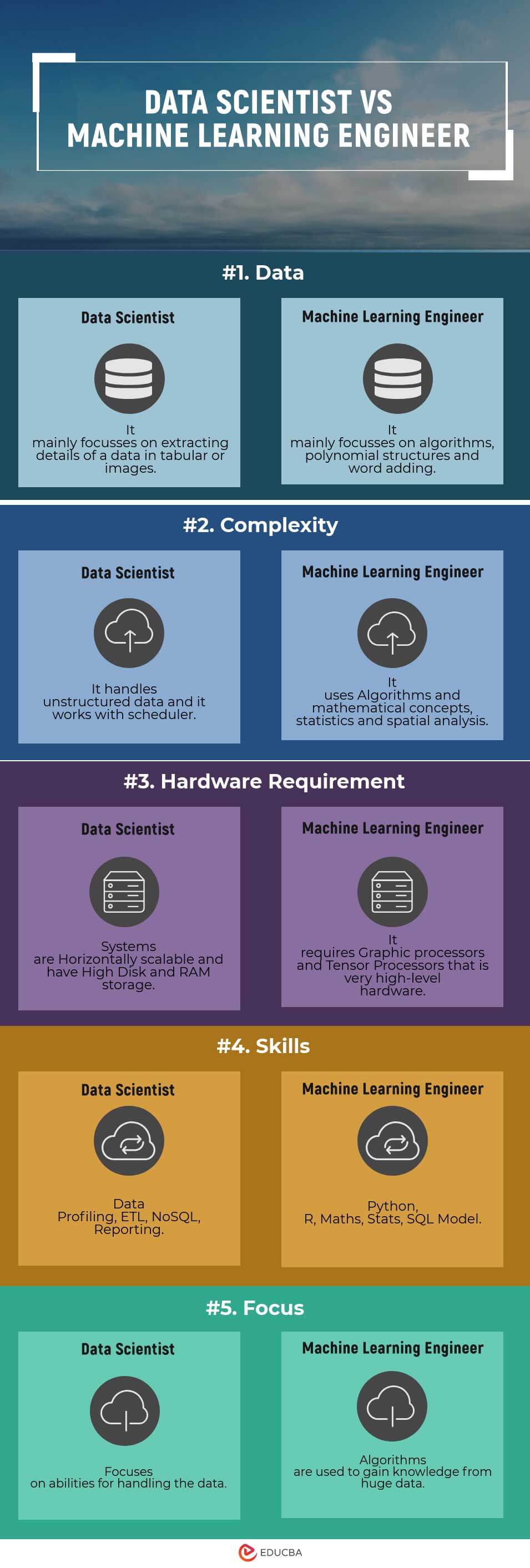
Data Scientist and Machine Learning Engineer Comparison Table
Following are the lists of points that describe the comparisons Between Data Scientist and Machine Learning Engineer:
| Feature | Data Scientist | Machine Learning Engineer |
| Data | It mainly focuses on extracting details of data in tabular or images. | It mainly focuses on algorithms, polynomial structures, and word adding. |
| Complexity | It handles unstructured data, and it works with a scheduler. | It uses Algorithms and mathematical concepts, statistics, and spatial analysis. |
| Hardware Requirement | Systems are Horizontally scalable and have High Disk and RAM storage. | It requires Graphic processors and Tensor Processors, that is very high-level hardware. |
| Skills | Data Profiling, ETL, NoSQL, Reporting. | Python, R, Maths, Stats, SQL Model. |
| Focus | Focuses on abilities to handle the data. | Algorithms are used to gain knowledge from huge amounts of data. |
Conclusion
Machine learning helps you learn the objective function, which plots the inputs to the target variable and independent variables to the dependent variables.
A Data scientist does a lot of data exploration and arrives at a broad strategy for tackling it. He is responsible for asking questions about the data and finding what answers one can reasonably draw from the data. Feature engineering belongs to the realm of Data scientists. Creativity also plays a role here, and a machine learning engineer knows more tools and can build models given a set of features and data – as per directions from the Data Scientist. The realm of Data preprocessing and feature extraction belongs to ML engineers.
Data science and examination utilize machine learning for this archetypal validation and creation. It is vital to note that all the algorithms in this model creation may not come from machine learning. They can arrive from numerous other fields. The model desires to be kept relevant always. If the situations change, the model we created earlier may become immaterial. The model must be checked for certainty at different times and adapted if its confidence is reduced.
Data science is a whole extensive domain. If we try to put it in a pipeline, it would have data acquisition, data storage, data preprocessing or cleaning, learning patterns in data (via machine learning), and using knowledge for predictions. This is one way to understand how machine learning fits into data science.
Recommended Articles
This is a guide to Data Scientist vs Machine Learning Engineer. Here we have discussed Data Scientist vs Machine Learning Engineer head-to-head comparison, key differences, infographics, and comparison tables. You may also look at the following articles to learn more –
