Updated July 6, 2023
Introduction to Data Replication
Data replication is the process of replicating data and storing it into different nodes or databases, or sites. Data replication is mainly utilized for high availability features. For business-critical systems, data replication is one of the best practices to avoid any impact due to server failure or system hardware related issues. Data replication helps in creating a distributed database system. Data replication is implemented for creating copies of the data on an ongoing basis rather than a batch of the static backup methods. Data replication ensures consistency of data across all the nodes by synchronizing with the sources. There are several methodologies and software applications available for implementing Data Replication.
Why do we Need Data Replication?
Data Replication is a process in the Database Management System (DBMS) that is relevant to maintain the data for the failover scenarios. In case of any primary database system goes down, the replication data will be useful for retrieving the data for the replication databases that help in the continuation of business operations. Data replication is also an integral concept and methodologies on the distributed system like Apache Hadoop that maintains at least three copies of the data set across the data nodes. The data replication mechanisms are very much essential for the high availability of data in the cluster-based distributed system.
How Does Data Replication Work?
Following is an overview diagram representing the data replication process and how it works:
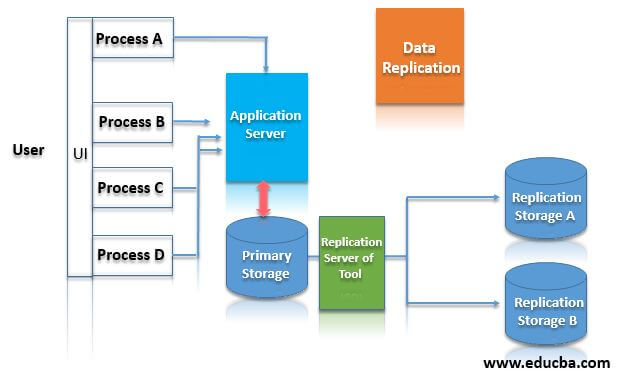
The Diagram represents Users interact with the system using the UI and the processes that create the data for the system. The system processes the data through the application server and stores it in the primary storage. Next to the replication server or tools processes the data replication.
Data replication works by creating or copying the same data into various start locations of the same or different hosts by creating data replica between two or multiple cloud-based hosts. Data replication can be provisioned on-demand or by transferring data in bulk mode or batch mode according to the schedule or by replicating in real-time as the data is written, modified, or deleted in the primary system.
There are different types of data replication process available such as transactional replication, Snapshot replication, and merge replication for various systems that are associated with the database.
Similarly, there can be full replication, which copies the whole data in every storage location and partial replication that copies only the relevant data, excluding the non-relevant data from the replication process.
In case the system not implementing the data replication, it is known as no replication.
#1. Full Replication
Full replication is the process of creating the exact replica of the data across multiple systems or sites. It is a best practice to follows as the business can get the data and enable the system even only one replication site is up.
Some of the benefits of full replication are high availability, faster query execution, and performance of the system based on the site locations. Similarly, some of the disadvantages of the full replication system are concurrency and a slow update process d require multiple due to the involvement of multiple data centers or locations.
#2. Partial Replication
Partial replication involves the segregation of the data into multiple sections or fragments. The number of sections depends on the data and business news that can be one or up to the total number of sites or nodes available on the distributed storage options. The description of the data section or fragments replication is known as the replication schema.
The major advantage of the partial Replication process is, it creates copies of the data based on the` important datasets instead of all the data. However, the disaster recovery process might be challenging in case the primary system gets major hardware failures and the whole system needs to be recovered.
Advantages and Disadvantages of Data Replication
In this section, we will discuss some of the benefits and pitfalls of the data replication process.
Advantages:
- Increases reliability and availability – Implementing data replication helps in increasing the reliability and availability of the system.
- Network performance improvement-Marinating the same copy of the data into multiple locations helps to reduce the data access latency. The data retrieval can be from an edge location data center that is managed by the data replication system. This improves network performance.
- Disaster recovery- It is a primary objective of data replication. Data replicas are very useful to recover the system from any major issue like hardware failures.
- Data analytics capabilities-Replicating data to a data warehouse system helps in creating data analytics solutions, and it provides the data for the business intelligence system.
- Test system performance improvement -The data replication process creates data for the test systems that require fast data accessibility and the same business data that the production systems use.
Disadvantages:
Although there are several advantages of data replication, however, there are certain disadvantages or challenges associated with data replication.
- Cost of implementation and maintenance – Marinating copies of the same data into multiple locations or storage devices requires storage and processing cost.
- The bandwidth of the resources-Maintaining data consistency across the locations or sites consumes network bandwidth.
- Time of implementation -Implementing and managing the full-fledged system for data replication requires a proper time frame and consumes efforts from technical time.
Applications of Data Replication in Various Fields
There are several applications of Data Replication in various fields such as:
1. Enterprise data maintenance of online transaction processing systems (OLTP) is very much important for disaster recovery and high availability.
2. Data replication mechanisms are implemented in multi-cloud environments to provide improved features like load balancing, effective response time, and availability. It streamlines the scalability in cloud computing.
3. Data replication is configured for big data systems like Apache Hadoop and Apache Spark that uses the replication factor to manage the number of copies the system will create.
4. Most of the advanced systems like SAP S/4 HANA supports a data replication framework.
Conclusion
Data Replication is an important process for data management that has certain advantages and disadvantages or pitfalls. Selecting the proper data replication process and implementing the appropriate tools for the processes based on the business requirements is important. Additionally, monitoring, logging, and alerting are the functions associated with Data replication.
Recommended Articles
This is a guide to Data Replication. Here we discuss the Introduction to Data Replication and its different types, Working along with Advantages and Disadvantages. You can also go through our suggested articles to learn more-
