What is Data Ingestion?
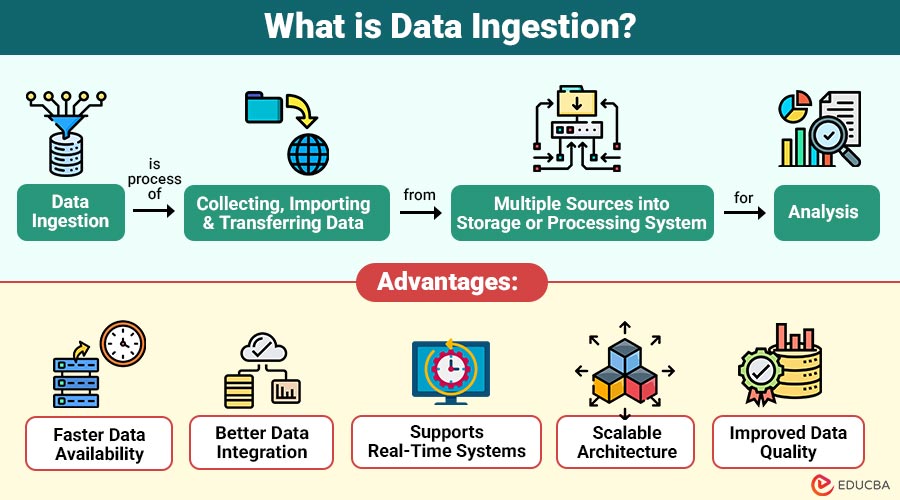
Data ingestion is process of collecting, importing, and transferring data from multiple sources into storage or processing system for analysis. It involves extracting data from various systems and loading it into platforms such as data warehouses, data lakes, or analytics tools.
Organizations ingest data from multiple sources, including:
- Databases
- APIs
- IoT devices
- Log files
- Social media platforms
- Enterprise applications
- Streaming platforms
The ingested data can then be processed, transformed, and analyzed to generate insights.
Table of Contents:
Key Takeaways:
- Data ingestion centralizes data from multiple sources, enabling faster access, analysis, and informed business decisions.
- Real-time ingestion supports instant processing, allowing organizations to monitor activities and respond quickly to changes.
- Ingestion pipelines handle structured, semi-structured, and unstructured data, improving integration, quality, and the accuracy of analytics.
- Batch, micro-batch, and lambda ingestion methods provide flexibility to process data efficiently according to business requirements.
Why is Data Ingestion Important?
Here are the key reasons why it plays a critical role in organizations:
1. Centralizes Data
Gathers information from different sources and stores it in a single system, making data easier to access, manage, and analyze.
2. Enables Real-Time Analytics
Real-time allows organizations to process incoming data immediately, helping them monitor activities, detect problems, and respond quickly to changes.
3. Supports Data Integration
Makes it easy to combine structured, semi-structured, and unstructured data from various systems into a single unified data platform.
4. Improves Decision Making
When data is ingested correctly and on time, organizations get accurate information that helps managers make better, faster, and more reliable decisions.
5. Required for Data Warehousing
Before storing information in data warehouses, data lakes, or databases, the data must first be collected, transferred, and ingested.
How Does Data Ingestion Work?
Data ingestion usually follows a pipeline.
Step 1 – Data Source
Data comes from different systems:
- Databases
- APIs
- Files
- Sensors
- Applications
Step 2 – Data Extraction
Data is collected from the source.
Step 3 – Data Transformation (Optional)
Data may be cleaned or formatted.
Step 4 – Data Loading
Data is stored in:
- Data warehouse
- Data lake
- Cloud storage
- Database
Step 5 – Data Processing
Data becomes ready for:
- Reporting
- Analytics
- Machine learning
Types of Data Ingestion
Here are the main types of data ingestion methods commonly used in organizations:
1. Batch Data Ingestion
Batch data ingestion is a method in which data is collected over time and loaded into the system at scheduled intervals.
2. Real-Time Data Ingestion (Streaming)
Real-time data ingestion is the process of continuously collecting and transferring data as it is generated from different sources.
3. Lambda Ingestion Architecture
Lambda ingestion architecture blends batch processing and real-time streaming to manage large volumes of data effectively, enabling both immediate processing and later analysis.
4. Micro-Batch Ingestion
Micro-batch ingestion is a method in which small amounts of data are collected frequently and processed in short intervals, rather than continuously streaming.
Tools Used for Data Ingestion
Here are some popular tools that help organizations efficiently collect, process, and transfer data:
1. Apache Kafka
Apache Kafka is a distributed platform designed for real-time streaming ingestion, enabling high-throughput, fault-tolerant, and scalable data pipelines efficiently.
2. Apache NiFi
Apache NiFi automates and manages data flow between systems, supporting data routing, transformation, and ingestion in real-time or batch modes.
3. Talend
Data from various sources can be effectively ingested, integrated, and transformed into centralized systems using Talend, an ETL software.
4. Informatica
Informatica is an enterprise-grade data integration tool used for ingesting, transforming, and managing large-scale data across various platforms.
5. AWS Glue
AWS Glue is a cloud-based service that automates data ingestion and ETL processes and prepares datasets for analytics in the cloud.
6. Google Dataflow
Google Dataflow allows you to handle both real-time and batch data, making it possible to stream, change, and analyze data across large
7. Azure Data Factory
Azure Data Factory is a cloud-based tool used for building, orchestrating, and automating pipelines efficiently at scale.
Use Cases of Data Ingestion
Here are key scenarios where IT plays a critical role in modern organizations:
1. Business Intelligence
Collects information into data warehouses, enabling organizations to generate reports, dashboards, and insights for efficient, informed decision-making.
2. Machine Learning
Machine learning models require data for training, validation, and testing to ensure accurate predictions and improved algorithm performance over time.
3. IoT Systems
IoT devices continuously generate data for monitoring, analytics, and automation, enabling real-time operational insights and decision-making.
4. Log Monitoring
Server, application, and system logs are ingested into centralized platforms to analyze performance, detect issues, and support troubleshooting.
5. Financial Transactions
Financial institutions ingest transaction data in real-time to detect fraud, monitor compliance, and ensure secure, accurate financial operations across platforms.
Advantages of Data Ingestion
Here are the main advantages of implementing efficient pipelines in organizations:
1. Faster Data Availability
Ensures information is collected, processed, and ready for analysis quickly, enabling timely business decisions.
2. Better Data Integration
Integrating data from various sources into a single system improves the consistency of reporting and analysis.
3. Supports Real-Time Systems
Enables live dashboards and monitoring systems to receive updated information for immediate insights continuously.
4. Scalable Architecture
Ingestion frameworks can efficiently handle increasing volumes of data, supporting growth and seamlessly expanding big data requirements.
5. Improved Data Quality
Pipelines can validate, cleanse, and transform data to ensure accuracy and reliability for analytics purposes.
Challenges in Data Ingestion
Here are the major challenges organizations face when implementing pipelines:
1. Large Data Volume
Handling massive datasets requires scalable infrastructure, optimized storage, and processing capabilities to ingest and manage big data efficiently.
2. Different Data Formats
Data comes in multiple formats, such as JSON, CSV, XML, logs, images, and videos, requiring flexible ingestion pipelines.
3. Data Quality Issues
Missing, inconsistent, or incorrect data values create challenges during ingestion, significantly impacting the accuracy of analytics, reporting, and decision-making.
4. Real-Time Processing Complexity
Streaming ingestion is complex to implement, requiring careful design to manage latency, concurrency, and fault tolerance effectively.
5. Network Latency
Slow network connections or bandwidth limitations can delay data transfer, affecting timely ingestion and real-time analytics performance.
6. Security Risks
Sensitive data must be protected during ingestion, requiring encryption, access controls, and consistent compliance with privacy regulations.
Real-World Examples
Here are practical scenarios demonstrating how data ingestion is applied across industries:
1. Online Food Delivery Platform
Data Sources:
- Customer orders from mobile apps
- Restaurant management system
- Payment gateway APIs
- User activity logs on website and app
Process:
- The streaming tool ingests orders and activity in real-time
- A data lake stores raw and historical data
- A data warehouse stores cleaned and aggregated data
- Dashboards provide insights into order trends, delivery times, and customer behavior
Use Cases:
- Monitor delivery performance in real time
- Personalized offers based on customer behavior
- Predictive analytics for demand forecasting
2. Smart City Traffic Management
Data Sources:
- Traffic sensors at intersections
- CCTV cameras
- GPS data from public transport
- Weather and road condition APIs
Process:
- Real-time streaming ingestion collects sensor and GPS data
- Cloud storage holds raw sensor feeds
- The analytics engine processes data for traffic patterns and congestion alerts
Use Cases:
- Real-time traffic monitoring and rerouting
- Accident detection and response
- Traffic flow optimization and urban planning
Final Thoughts
Data ingestion forms the backbone of modern data systems, enabling organizations to collect and transfer data from multiple sources into storage for processing and analysis. Whether batch, streaming, or hybrid, efficient ingestion pipelines ensure rapid, scalable, and reliable data flow. With big data, the cloud, and real-time analytics, it drives better insights, quicker decisions, and improved performance.
Frequently Asked Questions (FAQs)
Q1. Is data ingestion part of ETL?
Answer: Yes, ingestion is usually the extraction and loading part of ETL.
Q2. What is real-time ingestion?
Answer: Real-time ingestion loads data instantly as it is created.
Q3. Where is ingested data stored?
Answer: In databases, data lakes, data warehouses, or cloud storage.
Q4. Can data ingestion handle unstructured data?
Answer: Yes, modern ingestion pipelines can process structured, semi-structured, and unstructured data from various sources.
Recommended Articles
We hope that this EDUCBA information on “Data Ingestion” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
