Introduction to AWS Data Pipeline
AWS Data Pipeline is a managed web service offering that is useful to build and process data flow between various compute and storage components of AWS and on premise data sources as an external database, file systems, and business applications. AWS Data pipeline builds on a cloud interface and can be scheduled for a particular time interval or event. It helps to collect, transform and process data as a logical data flow with business logic among various components. AWS data pipeline service is reliable, scalable, cost-effective, easy to use and flexible .It helps the organization to maintain data integrity among other business components such as Amazon S3 to Amazon EMR data integration for big data processing.
Need for Data Pipeline
Let us try to understand the need for data pipeline with the example:
Example #1
We have a website that displays images and gifs on the basis of user searches or filters. Our primary focus is on serving content. There are certain goals to achieve that are as follows:-
- Improving Content Delivery: Serving what users want efficiently and fast enough.
- Manage the Application Efficiently: Storing the user data as well as website logs for later analytical purposes.
- Improve the Business: Using the stored data and analytics takes the decision to make business better at a cheaper cost.
Example #2
There are Certain Bottlenecks to be taken care of for Achieving the Goals:
- The huge amount of data in different formats and in different places which makes processing, storing and migrating data complex task.
Different Data Storage Components for different types of data:
- Possible real-time data for the registered users: Dynamo DB.
- Web-server logs for potential users: Amazon S3.
- Demographics data & login credentials: Amazon RDS.
- Sensor data & 3rd party dataset: Amazon S3.
Solutions
- Feasible Solution: We can see we have to deal with different types of tools to convert data from unstructured to structured for analysis. Here we have to use different tools to store data and again to convert, analyze and store processed data. Not a cost-effective solution.
- Optimal Solution: Use a data pipeline that handles processing, visualization, and migration. Data pipeline can be useful in the migration of data from different places, also analyzing data and processing at the same location on your behalf.
What is the AWS Data Pipeline?
AWS Data Pipeline is basically a web service offered by Amazon that helps you to Transform, Process, and Analyze your data in a scalable and reliable manner as well as storing processed data in S3, DynamoDb or your on-premises database.
- With AWS Data Pipeline you can Easily Access Data from Different Sources.
- Transform and Process that Data at Scale.
- Efficiently Transfer results to other services such as S3, DynamoDb table or on-premises data store.
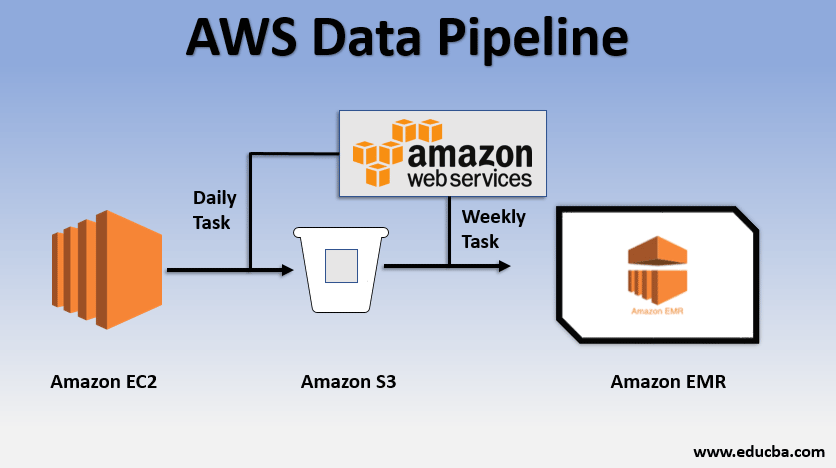
Basic Usage Example of the Data Pipeline
- We could have a website deployed over EC2 which is generating logs every day.
- A simple daily task could be copied log files from E2 and achieve them to the S3 bucket.
- A weekly task could be to process the data and launch data analysis over Amazon EMR to generate weekly reports on the basis of all collected data.
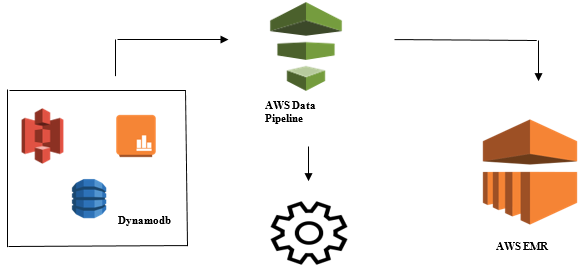
Launching Data Analysis with AWS Data Pipeline
- Collecting the data from different data sources like – S3, Dynamodb, On-premises, sensor data, etc.
- Performing transformation, processing, and analytics on AWS EMR to generate weekly reports.
- Weekly report saved in Redshift, S3 or on-premise database.
Benefits of AWS Data Pipeline
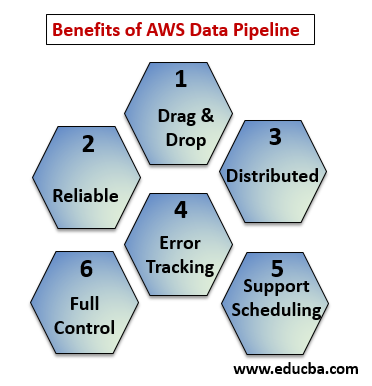
Below the points explain the benefits of AWS Data Pipeline:
- Drag and Drop console which is easy to understand and use.
- Distributed and Reliable Infrastructure: Data pipelines runs on scalable services and are reliable if any error or task fails it can be set to retry.
- Supports Scheduling and Error Tracking: You can schedule your tasks and track them what got fail and success.
- Distributed: Can be run on parallelly on multiple machines or in a linear fashion.
- Full control over computational resources like EC2, EMR clusters.
AWS Data Pipeline Components
Below are the components of the AWS Data Pipeline:
1. Pipeline Definition
Convert your business logic into the AWS Data Pipeline.
- Data Nodes: Contains the name, Location, Format of data source it could be (S3, dynamodb, on-premises)
- Activities: Move, Transform or perform queries on your data.
- Schedule: Schedule your daily or weekly activities.
- Pre-condition: Conditions like to start scheduler check data availability at the source.
- Resources: Compute resources EC2, EMR.
- Actions: Update about Data Pipeline, Sending Notifications, Trigger Alarm.
2. Pipelines
Here you schedule and run the tasks to perform defined activities.
- Pipeline Components: Pipeline components are the same as the components of the Pipeline definition.
- Instances: While running tasks AWS compiles all the components to create certain actionable instances. Such instances have all the information about specific tasks.
- Attempts: We already discussed how reliable the Data Pipeline is with its retry mechanisms. Here you set how many times you want to retry the task in case it fails.
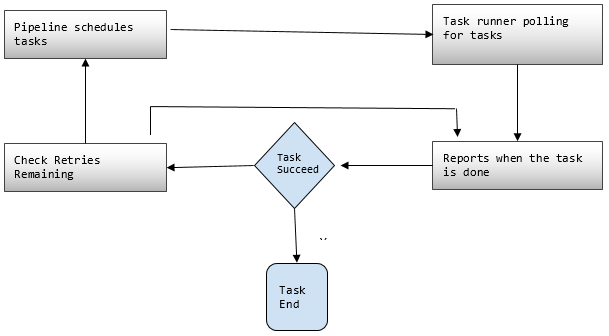
3. Task Runner
Asks or polls for tasks from the AWS Data Pipeline and then performs those tasks.
AWS Data Pipeline Pricing
Below the points explain the AWS Data pipeline pricing:
1. Free Tier
You can get started with AWS Data Pipeline for free as part of the AWS free usage tier. New sign up customers gets every month some free benefits for one year:
- 3 Preconditions of low frequency running on AWS without any charge.
- 5 Activities of low frequency running on AWS without any charge.
2. Low Frequency
Low Frequency is meant to be running one time in a day or less. Data Pipeline follows the same billing strategy as other AWS web services i.e, billed on your usage. It is billed upon how often your tasks, activities, and preconditions runs every day and where they run (AWS or on-premises). High-frequency activities are scheduled to run more than once a day.
Example: We can schedule an activity to run every hour and process the website logs or it could be every 12 hours. Whereas, Low-frequency activities are those that run once a day or less if the preconditions are not fulfilled. Inactive pipelines have either INACTIVE, PENDING, and FINISHED states.
3. Pricing of AWS Data Pipeline shown Region wise
Region #1: US East (N.Virginia), US West (Oregon), Asia Pacific (Sydney), EU (Ireland)
| High Frequency | Low Frequency | |
| Activities or preconditions running over AWS | $1.00 per month | $0.06 per month |
| Activities or preconditions running on-premises | $2.50 per month | $1.50 per month |
| Inactive Pipelines: $1.00 per month |
Region #2: Asia Pacific (Tokyo)
| High Frequency | Low Frequency | |
| Activities or preconditions running over AWS | $0.9524 per month | $0.5715 per month |
| Activities or preconditions running on-premises | $2.381 per month | $1.4286 per month |
| Inactive Pipelines: $0.9524 per month |
The pipeline that a daily job i.e a Low-Frequency activity on AWS to move data from DynamoDB table to Amazon S3 would cost $0.60 per month. If we add EC2 to produce a report based on Amazon S3 data, the total pipeline cost would be $1.20 per month. If we run this activity every 6 hours it would cost $2.00 per month, because then it would be a high-frequency activity.
Conclusion
AWS Data Pipeline is a very handy solution for managing the exponentially growing data at a cheaper cost. It is very reliable as well as scalable according to your usage. For any business need where it deals with a high amount of data, AWS Data Pipeline is a very good choice to reach all our business goals.
Recommended Articles
This is a guide to the AWS Data Pipeline. Here we discuss the needs of the data pipeline, what is AWS data pipeline, it’s component and pricing detail. You can also go through our other related articles to learn more –

