Updated March 24, 2023
What is Artificial Intelligence Algorithm?
Artificial Intelligence Algorithm is a field of study where we want computers to do the things which humans do. Obviously, computers are faster when it comes to calculation and analytical abilities, but computers cannot take decisions on their own, that is they don’t have the ability to make a decision. Empowering computers to make a decision with their own intelligence is Artificial Intelligence.
Now the question is, how can this be done?
Here we come across Artificial Intelligence algorithms. These special algorithms are capable of finding patterns and coming up with a process to make a decision. These AI algorithms are applied in a wide variety of fields such as robotics, marketing, business analytics, agriculture, healthcare, etc.
Categories of Artificial Intelligence Algorithm
Artificial Intelligence algorithm is a broad field consisting of Machine Learning algorithms and Deep Learning Algorithms. These algorithms’ main goal is to enable computers to learn on their own and make a decision or find useful patterns. Artificial Intelligence algorithms Learn from the data itself. In a broader sense, learning can be divided into 3 categories:
- Supervised Learning: When input and output, both labels are known, and the model learns from data to predict output for similar input data.
- Unsupervised Learning: When output data is unknown, or it is needed to find patterns in data given, such type of learning is unsupervised learning.
- Reinforcement Learning: Algorithms learn to perform an action from experience. Here algorithms learn through trial and error, which action yields the greatest rewards. The objective is to choose actions that maximize the expected reward over a given amount of time.
According to problems that humans encounter and solve, there are three categories in which these algorithms can be divided to perform the same actions.
- Classification: Humans do make decision-based on classification; for example, Will this shirt look good on me or not? So here, the human mind will process some algorithm with previous experience (data), and then the output will be yes or no. In the same way, these classification algorithms will take some input data and based on this. It will predict yes or No. Some examples of these algorithms are Naïve Bayes, logistic regression, SVM, etc.
- Regression: Here, the output is continuous; there is no specific category. For example, what will be the temperature tomorrow? A human mind will think of the season and temperature of previous days and will predict some number. Some examples of these algorithms are Linear regression, gradient boosting, random forest, etc.
- Clustering: Sometimes, we don’t have to make a decision on given input but distinguishing odd ones. For example, segregating different human race white people and black people or seeing a painting and finding different patterns. Some examples of these algorithms are K-means clustering, Hierarchical clustering, etc.
We will discuss one algorithm from each category:
1. Naïve Bayes
- It is used for the classification problem, and it assumes that predictors are independent and have one feature that does not affect another predictor feature.
- For e.g., orange may be considered as orange in color, round in shape, and about 6 cm in diameter. All these variables do not depend on each other or maybe on the existence of the another, but all these features independently contribute to the fact that fruit is an orange and that is the reason it is called ‘Naive’.
- Naive Bayes model is used for a very large data set. It is simple and outperforms highly sophisticated classification models also.
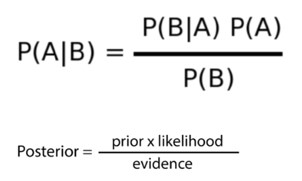
- Naïve Bayes Classifier is based on Bayesian probability used to calculate posterior probability (processing new evidence and refine the hypothesis at each step). In Naïve Bayes’ the probability with each independent variable is calculated and then with the Bayesian approach is used for predicting outcome.
2. Random Forest
- Random Forest is a version of Ensemble Learning and is used for regression problems though it can also be used for classification problems.
- Ensemble Learning: Take multiple algorithms or the same algorithm multiple times, and then it puts them together to make something much more powerful than the single decision tree.
- In Random Forest, we take a number of decision trees to predict output. Then we ensemble them with an ensemble algorithm that will further take count/average of output from all the decision trees and predict the final outcome.
- Ensemble Algorithms are more stable because any change in your dataset can affect your decision tree, but for them to affect the forest of a tree is far more difficult than gives stability to the model.
3. K-Means Clustering
This is an algorithm that is used for unsupervised learning. K is the number of clusters we want. We can understand it in 5 basic steps:
- For K clusters, we chose k random data points which are called Initial Centroids.
- Find Euclidian distance from data points to centroids and assign each data point to the closest centroid. (take mean and assign it to data points).
- Recompute the Euclidian distance from new cluster positions to all the data points.
- Take mean and assign this as new clusters centroid.
- Keep repeating until convergence is met.
The algorithm can be terminated when it reaches the iteration budget. K-means is sensitive to the scale of data, so it is recommended to standardize the dataset before running this algorithm.
Conclusion
Artificial Intelligence algorithm is a broad field consisting of Machine Learning algorithms and Deep Learning Algorithms. Artificial Intelligence algorithms give machines the ability to make decisions, recognize patterns and draw useful conclusions which basically means imitating human intelligence. In the above article, we have explored the wide area for an approach for learning (Supervised, Unsupervised, and Reinforcement learning) where these algorithms are used to draw conclusions. Further, these algorithms are categorized into three categories according to the type of problems namely: classification, regression and clustering methods. We have discussed Naïve Bayes’ algorithm for classification, Random forest algorithm for regression, and K-means clustering algorithm for the clustering problem.

