What is Data Simulation?
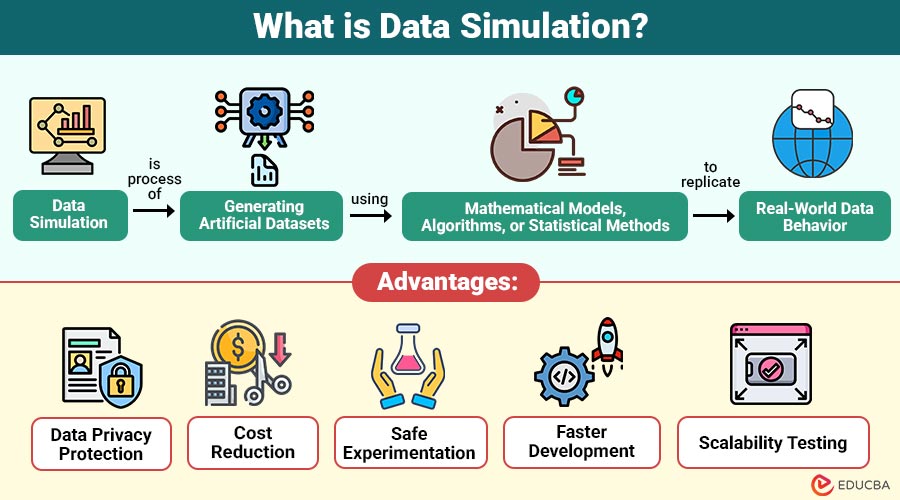
Data simulation is the process of generating artificial datasets using mathematical models, algorithms, or statistical methods to replicate real-world data behavior.
In simple terms, it creates synthetic data that behaves like actual data but does not contain real information.
Key Characteristics:
- Generates artificial but realistic data
- Replicates patterns of real datasets
- Used for testing, modeling, and experimentation
- Protects sensitive information
- Supports research and development activities
Table of Contents:
Key Takeaways:
- Data simulation generates artificial datasets using mathematical models to replicate real-world data patterns for safe testing and analysis.
- It is widely used in machine learning, finance, healthcare, and software testing when real data is unavailable or sensitive.
- Data simulation allows organizations to test extreme, risky, or large-scale scenarios safely without affecting real systems or users.
- Although useful, simulated data depends on model accuracy and cannot completely replace real-world data in all situations.
How Does Data Simulation Work?
Data simulation typically follows a structured process. The goal is to create data that accurately reflects patterns and distributions of real-world data.
1. Define Objectives
The first step in data simulation is defining the objective, such as testing software performance, training machine learning models, or analyzing different business scenarios.
2. Build a Mathematical Model
A mathematical or statistical model is created using rules, formulas, probability distributions, or algorithms to accurately represent real-world processes and system behavior.
3. Generate Synthetic Data
Using the designed model, synthetic data is generated that resembles real-world datasets in structure, format, relationships, and patterns. This is done for testing purposes.
4. Validate the Data
The generated data is validated by comparing it with real datasets to ensure accuracy, consistency, reliability, and that it correctly follows expected statistical distributions.
5. Use Data for Analysis
After validation, the simulated data is used for analysis, experiments, system testing, training machine learning models, and evaluating different possible scenarios safely.
Types of Data Simulation
Data simulation can be categorized into several types depending on how the artificial data is generated.
1. Monte Carlo Simulation
Monte Carlo simulation is a data generation method that uses repeated random sampling to model uncertainty, probability distributions, and multiple possible outcomes in complex systems.
Key Features:
- Uses random variables
- Simulates thousands of possible outcomes
- Commonly used in risk analysis and finance
2. Agent-Based Simulation
Agent-based simulation is a data simulation technique that models the actions and interactions of individual agents to comprehend the behavior and performance of complex systems over time.
Key Features:
- Each agent follows specific rules
- Agents interact with each other
- Used to model complex systems
3. Discrete Event Simulation
Discrete event simulation is a method that generates data by modeling systems where state changes occur at specific events, helping analyze workflows, operations, and process efficiency.
Key Features:
- Event-driven
- Used for operational systems
- Helps analyze workflows
4. Continuous Simulation
Continuous simulation is a data simulation approach that models systems in which variables change continuously over time, using mathematical equations to represent real-world physical or dynamic processes.
Key Features:
- Variables change continuously over time
- Uses mathematical formulas and differential equations
- Suitable for physical, biological, and environmental systems
5. Synthetic Data Generation
Synthetic data generation is process of creating artificial datasets that replicate real-world data patterns while protecting sensitive information and is commonly used in testing, analytics, and machine learning.
Key Features:
- Protects privacy
- Used in machine learning
- Mimics real datasets
Techniques Used in Data Simulation
Several techniques are used to simulate realistic datasets.
1. Statistical Modeling
Statistical modeling generates artificial data using probability distributions like normal, Poisson, or binomial, accurately replicating patterns observed in real-world datasets.
2. Machine Learning Models
Machine learning models, including GANs and VAEs, generate synthetic data by learning patterns in existing data, producing highly realistic artificial datasets for experiments.
3. Rule-Based Simulation
Rule-based simulation generates data according to predefined logical rules, such as simulating e-commerce customer purchases based on specific browsing and interaction behaviors.
4. Random Data Generation
Random data generation creates datasets using random numbers within defined ranges, though this approach may not accurately capture real-world complexity.
Applications of Data Simulation
Data simulation is used across many industries and technologies.
1. Machine Learning and AI
Data simulation generates synthetic training datasets for machine learning and AI models when real-world data is limited or unavailable.
2. Software Testing
Developers use data simulation to create large datasets for testing software performance, scalability, and system reliability under varying conditions.
3. Healthcare Research
Healthcare organizations simulate patient data to analyze diseases, evaluate treatments, and conduct research without exposing real patient information.
4. Financial Risk Analysis
Financial institutions simulate market conditions and asset behaviors to assess investment risks, portfolio performance, and economic uncertainty effectively.
5. Manufacturing and Operations
Manufacturers simulate production lines, machinery, and workflows to enhance efficiency, optimize processes, and minimize downtime or operational delays.
6. Cybersecurity Testing
Security professionals simulate cyberattack scenarios to evaluate defenses, identify vulnerabilities, and improve the effectiveness of cybersecurity systems and protocols.
Advantages of Data Simulation
Data simulation provides several advantages for organizations and researchers.
1. Data Privacy Protection
Simulated data does not include real personal information, ensuring privacy and minimizing the risk of sensitive data exposure.
2. Cost Reduction
Organizations can perform experiments, testing, and analysis without incurring costs associated with collecting and managing real-world datasets.
3. Safe Experimentation
Data simulation allows testing extreme or hazardous scenarios safely, such as evaluating aircraft system failures or critical infrastructure risks.
4. Faster Development
Developers quickly generate large synthetic datasets to accelerate software testing, machine learning model training, and application development.
5. Scalability Testing
By simulating millions of records, developers can evaluate systems under heavy loads, ensuring performance, reliability, and stability under stress.
Limitations of Data Simulation
Despite its advantages, data simulation also has some limitations.
1. Accuracy Challenges
Simulated data may inadequately capture real-world complexity, leading to results that misalign with actual scenarios.
2. Model Dependency
The effectiveness of data simulation depends on the accuracy, assumptions, and design of the mathematical or logical model used.
3. High Computational Cost
Complex data simulations require powerful hardware, large memory, and high processing time, increasing overall computational cost and resource usage.
4. Risk of Bias
If the simulation model contains incorrect assumptions or bias, the generated data may lead to misleading analysis and wrong decisions.
Real-World Examples
Here are some common real-world examples where data simulation is used to model situations, test systems, and predict outcomes safely and efficiently.
1. Autonomous Vehicle Training
Self-driving vehicle systems use data simulation to create millions of driving scenarios, including accidents, pedestrians, and weather conditions, to train AI safely.
2. Pandemic Modeling
Scientists use data simulation to model disease spread, predict infection rates, evaluate control measures, and effectively plan healthcare responses during outbreaks.
3. Banking Risk Assessment
Banks use computer simulations to copy market changes, interest rates, and economic situations to check risks, test investments, and make safer financial decisions.
4. Retail Demand Forecasting
Retail companies use simulations to understand how customers buy products, how demand changes in different seasons, and how much stock is needed to avoid shortages or waste.
5. Smart City Planning
Urban planners simulate traffic flow, energy usage, population growth, and infrastructure needs to design efficient, sustainable, and well-managed smart city environments.
Final Thoughts
Data simulation is a powerful technique for generating artificial datasets that closely mimic real-world data behavior for testing, research, and analysis. It supports machine learning, software development, financial modeling, and scientific studies by enabling safe experimentation, protecting sensitive information, and creating scalable data. Its effectiveness depends on accurate models, proper validation, and realistic assumptions.
Frequently Asked Questions (FAQs)
Q1. What tools are used for data simulation?
Answer: Common tools include Python, R, MATLAB, AnyLogic, Simul8, and various machine learning frameworks.
Q2. Is simulated data accurate?
Answer: Simulated data can be accurate if the underlying models correctly represent real-world patterns.
Q3. Can simulated data replace real-world data?
Answer: Simulated data cannot fully replace real data, but it is useful when real data is limited, unavailable, or sensitive and is often combined for better accuracy.
Recommended Articles
We hope that this EDUCBA information on “Data Simulation” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
