What is Data Annotation?
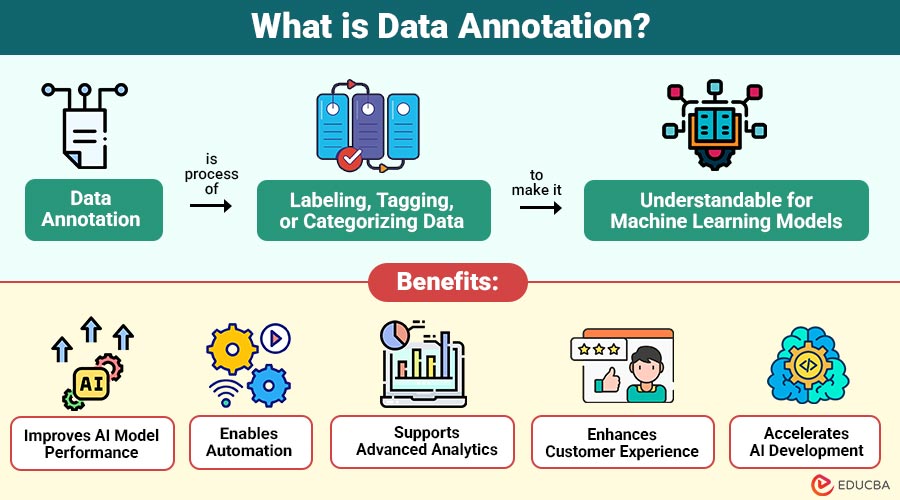
Data annotation is the process of labeling, tagging, or categorizing data to make it understandable for machine learning models. In order for algorithms to extract patterns and relationships from the data, it entails adding information to datasets.
Example:
- Labeling images of animals as cat, dog, or bird
- Marking objects such as cars, pedestrians, and traffic lights in self-driving car datasets
- Tagging text with sentiment labels such as positive, negative, or neutral
AI models may learn and carry out tasks like picture recognition, speech processing, and language translation by using these annotations as training data.
Table of Contents:
Key Takeaways:
- Data annotation labels raw data so machine learning models learn patterns and make predictions.
- High-quality annotated datasets greatly improve the accuracy, performance, and reliability of artificial intelligence systems.
- Different annotation types, such as image, text, audio, and video, support various AI applications effectively.
- Proper annotation workflows, tools, and quality checks ensure scalable, secure, and efficient AI development.
Why is Data Annotation Important?
Data annotation is an important step in building effective machine learning systems. Without properly labeled data, algorithms cannot learn meaningful patterns.
1. Improves Machine Learning Accuracy
Annotated data allows algorithms to learn from structured examples, improving model accuracy and prediction performance.
2. Enables AI Training
Machine learning models require large volumes of labeled data to train effectively. Annotation provides the required labels.
3. Enhances Data Quality
Annotation helps organize and structure raw data, making it more useful for analysis and training.
4. Supports Advanced AI Applications
Annotated datasets are essential to technologies like voice assistants, recommendation systems, and driverless cars.
5. Helps Build Intelligent Systems
Annotated data helps AI systems understand real-world objects, speech, and text.
Types of Data Annotation
Here are the main types of data annotation used to train AI and machine learning models for different kinds of data.
1. Image Annotation
The process of naming objects, areas, or features in photos to train computer vision models for precise object detection is known as image annotation.
2. Text Annotation
Text annotation is the process of labeling words, sentences, or documents to help natural language processing models understand meaning, sentiment, and context correctly.
3. Audio Annotation
Audio annotation is process of labeling sound recordings with transcripts, speaker details, or emotions to train speech recognition and sound classification systems.
4. Video Annotation
Video annotation is process of labeling objects, actions, or events across multiple video frames to train AI models for tracking and activity recognition.
5. Semantic Annotation
Semantic annotation is the process of adding contextual meaning to words or data by linking them to concepts, categories, or relationships to improve understanding.
Data Annotation Techniques
Different techniques are used to label data depending on the application and dataset.
1. Bounding Boxes
Bounding boxes are rectangular frames drawn around objects in images to help machine learning models detect, classify, and locate objects accurately during training.
2. Polygon Annotation
Polygon annotation uses multiple connected points to outline objects precisely, enabling accurate labeling of irregular shapes for detailed training of computer vision models.
3. Landmark Annotation
Landmark annotations mark specific key points on objects, such as eyes, noses, and joints, to train models for facial recognition, pose detection, and tracking.
4. Semantic Segmentation
Semantic segmentation assigns a category to every pixel in an image, enabling machine learning models to accurately capture object boundaries, backgrounds, and scene details.
5. Text Tagging
Text tagging labels words, phrases, or sentences with categories or meanings to help natural language processing models understand context, intent, and relationships in text.
Data Annotation Tools
Various tools are available to simplify data annotation. These tools help organizations efficiently label large datasets.
1. Labelbox
Labelbox is a data annotation platform used for labeling images, videos, and text datasets for machine learning and artificial intelligence training.
2. Computer Vision Annotation Tool
The Computer Vision Annotation Tool is an open-source tool designed for computer vision tasks, including image labeling, object tracking, and video annotation.
3. Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is a cloud-based data labeling service that provides automated and human annotation for machine learning training datasets.
4. Prodigy
Prodigy is a machine-learning annotation tool primarily used for natural-language processing tasks such as text classification, tagging, and entity recognition.
5. SuperAnnotate
SuperAnnotate is an advanced annotation tool that supports image and video labeling with collaborative features for artificial intelligence and deep learning projects.
Data Annotation Workflow
The data annotation process typically follows a structured workflow.
Step 1: Data Collection
Data collection is process of gathering raw data, such as images, text, audio, or video, from multiple sources for annotation purposes.
Step 2: Data Preparation
Data preparation involves cleaning, filtering, formatting, and organizing collected data to ensure it is consistent, accurate, and ready for annotation tasks.
Step 3: Annotation Process
During annotation, trained annotators label data using predefined guidelines and annotation tools so machine learning models can understand patterns and relationships.
Step 4: Quality Review
Quality review checks annotated data for errors, inconsistencies, or missing labels to ensure high accuracy before using the dataset for training models.
Step 5: Model Training
In order to educate machine learning algorithms to identify patterns, make predictions, and carry out tasks correctly, model training makes use of annotated datasets.
Step 6: Model Evaluation
Model evaluation tests the trained model using annotated validation data to measure accuracy, identify errors, and improve overall machine learning performance.
Benefits of Data Annotation
Data annotation offers several benefits for organizations building AI systems.
1. Improves AI Model Performance
High-quality annotated data helps machine learning models learn correct patterns, leading to higher accuracy, more reliable predictions, and improved overall artificial intelligence performance.
2. Enables Automation
AI systems can automatically carry out activities like picture identification, speech processing, and decision-making in the retail, transportation, and healthcare sectors thanks to annotated datasets.
3. Supports Advanced Analytics
Properly labeled data makes it easier to analyze information, discover patterns, generate insights, and support data-driven decision-making in modern business intelligence systems.
4. Enhances Customer Experience
AI systems that have been trained on annotated data can offer tailored suggestions, precise answers, and quicker service, greatly enhancing user experience and customer satisfaction.
5. Accelerates AI Development
Efficient data annotation speeds up machine learning development by providing high-quality training datasets, reducing errors, saving time, and improving overall project productivity and performance.
Challenges in Data Annotation
Despite its importance, data annotation presents several challenges.
1. Time-Consuming Process
Annotating large volumes of data requires significant human effort and time, especially when high accuracy and detailed labeling guidelines must be followed carefully.
2. High Cost
Manual data annotation often requires skilled human annotators, specialized tools, and quality review processes, significantly increasing the overall project cost for organizations.
3. Data Quality Issues
Incorrect, inconsistent, or incomplete annotations can reduce dataset quality, causing machine learning models to learn wrong patterns and produce inaccurate predictions or results.
4. Scalability Problems
As datasets grow larger, managing annotation tasks becomes difficult, requiring more resources, better tools, and efficient workflows to maintain speed and accuracy.
5. Privacy and Security Concerns
Annotating sensitive data, such as medical, financial, or personal information, requires strict security measures to protect privacy and ensure proper compliance with legal regulations.
Real-World Applications of Data Annotation
Here are some common real-world applications where data annotation is widely used in artificial intelligence and machine learning systems.
1. Autonomous Vehicles
Autonomous vehicles use annotated images and videos to recognize road signs, pedestrians, vehicles, and obstacles, helping self-driving systems make safe driving decisions.
2. Healthcare
Healthcare systems use annotated medical images, such as X-rays, CT scans, and MRIs, to detect diseases, tumors, and abnormalities with greater accuracy using AI.
3. E-Commerce
E-commerce platforms use annotated product data to improve search accuracy, recommendation systems, product categorization, and personalized shopping experiences for customers online.
4. Social Media Platforms
Social media platforms use annotated datasets to detect spam, harmful content, fake accounts, and inappropriate posts, improving safety, moderation, and user experience.
5. Virtual Assistants
Virtual assistants use annotated audio and text datasets to understand speech, recognize commands, process language, and automatically provide accurate responses to user requests.
Final Thoughts
Data annotation is an essential part of artificial intelligence and machine learning, involving labeling raw data to make it usable for training models. It helps systems recognize patterns, understand language, and make accurate decisions. Despite being time-consuming, modern tools and automation improve efficiency, making annotated data crucial for future AI development and innovation.
Frequently Asked Questions (FAQs)
Q1. What types of data can be annotated?
Answer: Common types include images, text, audio, and video data.
Q2. Why is data annotation important for AI?
Answer: It provides labeled training data that helps AI systems understand and interpret information.
Q3. Is data annotation done manually or automatically?
Answer: It can be done manually, automatically using AI tools, or through a combination of both.
Q4. What industries use data annotation?
Answer: Industries such as healthcare, automotive, retail, social media, and finance use data annotation for AI applications.
Recommended Articles
We hope that this EDUCBA information on “Data Annotation” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
