What are Diffusion Models?
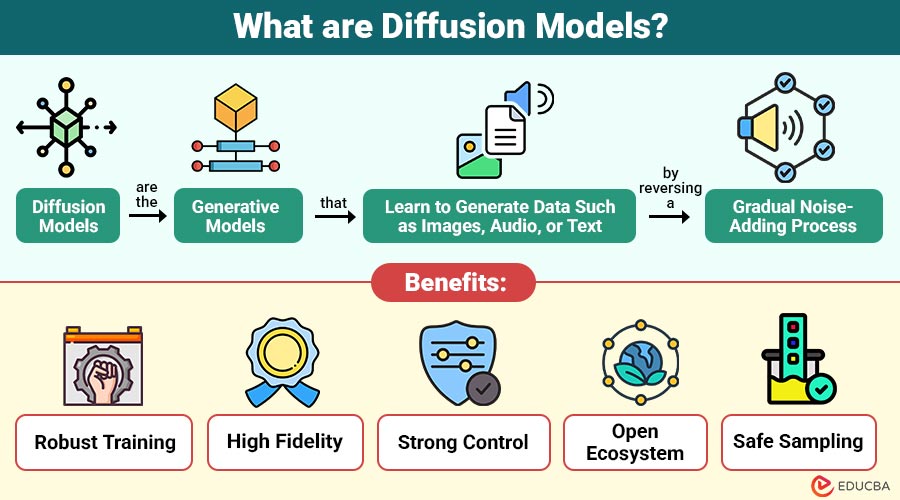
Diffusion models are the generative models that learn to generate data (such as images, audio, or text) by reversing a gradual noise-adding process.
The central idea is:
- Forward Diffusion (Noise Addition): Data is progressively corrupted by adding Gaussian noise at each step.
- Reverse Diffusion (Denoising): A neural network learns to reverse the effects of this noise, step by step, to reconstruct data from pure noise.
The model eventually learns to generate entirely new samples by starting from random noise and denoising it into meaningful structures.
Table of Contents:
- Meaning
- Working
- Components
- Types
- Why did Diffusion Models Become Popular?
- Benefits
- Limitations
- Real-World Examples
Key Takeaways:
- Diffusion models excel at generating diverse, high-quality outputs while maintaining training stability across multiple applications.
- Working in latent or compressed spaces significantly reduces computational cost without sacrificing image, video, or audio fidelity.
- Conditional and guided diffusion techniques offer fine-grained control, enabling task-specific outputs for creative and scientific workflows.
- Despite slower inference, diffusion models’ robustness, scalability, and open-source ecosystem drive rapid innovation in AI research.
How Diffusion Models Work?
Here are the key stages that explain how it generate new data.
1. Forward Process (Adding Noise)
- The model takes a real image.
- It adds small amounts of noise incrementally.
- After many steps, the image turns into random noise.
- Each step follows a simple mathematical transformation based on the Gaussian distribution.
This forward process is fixed—no learning happens here.
2. Reverse Process (Removing Noise)
- A neural network, often a U-Net, learns to predict the noise added at each step.
- For every noisy sample, it predicts a slightly denoised version.
- Repeating this for hundreds or thousands of steps recreates a realistic image.
The model learns this reverse process during training.
3. Sampling
Once trained, the model can:
- Start with pure noise
- Gradually remove noise using learned steps
- Generate completely new images, videos, or audio
This is the phase used in tools like Stable Diffusion, Midjourney, and DALL·E.
Key Components of Diffusion Models
Here are the key components—and some models even use magical quantum noise for instant image generation!
1. Noise Schedule
A noise schedule determines the amount of noise added per diffusion step, significantly affecting model training stability and the quality of generated samples.
2. Denoising Network
The denoising network, often a U-Net variant, predicts noise or clean data using attention and transformer-based architectural enhancements.
3. Timesteps
Operates over multiple timesteps, where more steps enhance output quality but increase computational cost and generation time.
4. Guidance Techniques
Guidance techniques steer model outputs using classifiers, classifier-free approaches, or prompt conditioning to ensure controlled, accurate generative results.
Types of Diffusion Models
Here are the main types of diffusion models:
1. Denoising Diffusion Probabilistic Models (DDPM)
DDPMs generate high-quality outputs by reversing the incremental noise addition but require many steps, slowing inference.
2. Denoising Diffusion Implicit Models (DDIM)
DDIMs achieve faster, deterministic sampling by modifying reverse diffusion, enabling efficient image generation in modern pipelines.
3. Latent Diffusion Models (LDMs )
LDMs work in compressed latent spaces, greatly improving efficiency and powering advanced generative models like Stable Diffusion.
4. Score-Based Models
Score-based models learn how data changes by using equations with randomness, enabling them to generate new data in a flexible and reliable way.
5. Conditional Diffusion Models
Conditional diffusion models use prompts, labels, or layouts to control outputs, supporting text-to-image, translation, and inpainting tasks.
Why did Diffusion Models Become Popular?
The rise can be traced to their strengths compared to older generative methods like GANs.
1. Stability
Train reliably, avoiding common GAN issues such as mode collapse and unstable adversarial training behaviors.
2. High-Quality Outputs
They generate sharp, realistic, and highly detailed images, outperforming many earlier generative models in visual fidelity.
3. Flexibility
Diffusion models efficiently support diverse tasks, including image synthesis, editing, inpainting, super-resolution, and even video generation.
4. Scalability
Latent diffusion models can grow very large and still produce high-quality images with less computing power.
5. Controllability
Prompt engineering and guidance methods enable precise control over generated outputs, yielding highly customizable, targeted results.
Benefits of Diffusion Models
It offers several benefits that make them increasingly popular in generative AI:
1. Robust Training
It avoids adversarial setups, providing stable, predictable training processes that reduce instability and mode collapse issues.
2. High Fidelity
They generate near-photorealistic, highly detailed outputs, achieving superior visual quality compared to many traditional generative approaches.
3. Strong Control
Fine-tuning, prompt guidance, and conditioning techniques effectively allow versatile control over outputs across multiple generation tasks.
4. Open Ecosystem
Open-source models like Stable Diffusion empower the community, driving rapid research, innovation, and accessible deployment of diffusion technology.
5. Safe Sampling
Predictable, stepwise noise reduction enables controlled, monitorable sampling, reducing the risk of unexpected or unsafe outputs.
Limitations of Diffusion Models
While diffusion models are powerful, they come with several limitations:
1. Slow Inference
It requires multiple denoising steps, resulting in slower inference than GANs or other generative approaches.
2. High Compute Cost
Training at scale requires powerful GPUs or many machines, making it costly and resource-intensive.
3. Large Storage Requirements
Model sizes can range from hundreds of megabytes to several gigabytes, creating challenges for storage and deployment.
4. Risk of Bias
Generated outputs can reflect biases in the training data, leading to unintended or socially sensitive content.
5. Difficulty With Global Consistency
It may struggle to maintain long-range relationships, textual accuracy, and coherence across multiple subjects or complex scenes.
Real-World Examples of Diffusion-Based Systems
Here are some popular diffusion-based systems widely used today:
1. Stable Diffusion
- Open-source latent diffusion model
- Excels at artistic and photorealistic image generation
- Supports fine-tuning, LoRA models, and custom datasets
2. DALL·E 3
- High prompt understanding
- Strong composition and text handling
- Integrated with creative workflows
3. Midjourney
- Artistic, stylized outputs
- Fast generation
- Popular for branding and creative work
Final Thoughts
Diffusion models have revolutionized generative AI by offering stability, flexibility, and unprecedented output quality. From art generation and video creation to scientific simulations and drug discovery, it now power some of the most advanced systems in artificial intelligence. As research continues to reduce the number of sampling steps, improve multimodal understanding, and scale up latent models, they are expected to dominate the next era of generative AI innovation.
Frequently Asked Questions (FAQs)
Q1. Can diffusion models generate text?
Answer: Yes, emerging multimodal diffusion systems can produce and edit text, though transformer-based LLMs remain dominant.
Q2. How many steps does a diffusion model usually take?
Answer: Often between 25 and 1000 steps, depending on quality vs. speed.
Q3. Do diffusion models require GPUs?
Answer: Training does, but inference can run on mid-range GPUs or optimized CPUs for smaller models.
Recommended Articles
We hope that this EDUCBA information on “Diffusion Models” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

