Updated June 14, 2023
Introduction to Redshift Node Types
The following article provides an outline for Redshift Node Types. Redshift provides different types of functionality to the user; the node is one of the functionalities provided by Redshift. Normally Redshift provides different types of nodes to manage the workload, so we have RA3 or DC2 nodes, but this depends on the performance, size of data, and growth.
The RC3 node we used to manage the storage system means that, as per requirement, we can scale the storage size and manage the storage system independently. By using RC3, we can select the number of nodes based on the performance requirement; after that, we can pay for used nodes.
Different Redshift Node Types
Given below are the different types of the node in Redshift:
An Amazon Redshift group comprises hubs. Each group has a pioneer hub and at least one figure hub. First, the pioneer hub gets inquiries from customer applications, parses the questions, and creates inquiry execution plans. Next, the pioneer hub then, at that point, arranges the equal execution of these plans with the process hubs and totals the transitional outcomes from these hubs. It then, at that point, at long last, returns the outcomes to the customer applications.
Register hubs execute the question execution designs and communicate information among them to serve these inquiries. The halfway outcomes are shipped off the pioneer hub for conglomeration before being returned to the customer applications.
Hubs are characterized by the beneath boundaries. While picking the hub, you need to painstakingly analyze the boundaries and pick the one that best suits your prerequisite. How about we have a definite gander at these boundaries?
- vCPU: This is the number of virtual CPUs for every hub.
- RAM: This is the measure of memory in gibibytes (GiB) for every hub.
- Cut per Node: The boundary characterizes the number of cuts the hubs are apportioned into when the bunch is made or resized.
- Capacity: This is the limit and kind of capacity for every hub.
- Node Range: These are the base and the greatest number of hubs that Amazon Redshift upholds for the hub type and size.
Types of nodes are as follows:
1. RA3 Node
AWS presented the RA3 hub in late 2019, and it is the third-era occurrence type for the Redshift family. RA3 includes high-velocity reserving, oversaw store, and high data transmission organizing. In the new RA3 age occurrence type, Redshift stores perpetual information to S3 and utilizes the neighborhood circle for reserving purposes. The information from S3 can be recovered on request, and consequently, the RA3 examples split the expense among figuring and capacity. You need to pay for capacity and processing per GB.
Given below are the different types of RA3 nodes:
- Ra3.4xlarge: This is the first type of RA3 node. It required 12 virtual CPUs for each node. This node uses 96 GB of RAM. So the Ra3.4xlarge is required, or we can say that it manages the 64 TB storage for each node, and the total capacity of this node is 4096 TB.
- Ra3.16xlarge: This is the second type of RA3 node. It required 48 virtual CPUs for each node. This node uses 384 GB RAM. The Ra3.16xlarge is required, or we can say that it manages the 64 TB storage for each node, and the total capacity of this node is 8192 TB.
Example:
Now let’s see how to create the new node inside the cluster.
First, we need to click on the snapshot button; inside that, we need to specify all node details, such as the node’s name, virtual CPU, RAM, and storage size, as shown in the screenshot below.
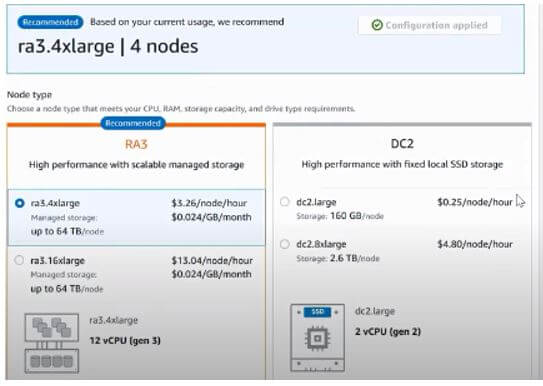
After selecting the required option, we can create the RA3.4xlarge node, as shown in the screenshot below.

See here we created RA3 with 4 nodes and 256 TB storage size as shown.
2. Dense Compute Node (DC2)
DC2 is advanced for handling information and is a registered concentrated information distribution center that utilizes SSD for neighborhood stockpiling. It lets you pick a few hubs depending on your information size and execution prerequisites. As a thumb rule, if you have fewer than 500 GB of information, it is prudent to go for DC2 occasion type as it can give magnificent calculation force and SSD for ideal stockpiling. Moreover, DC2 stores the information locally for the elite, allowing you to add more register hubs if you need additional room.
Given below are the different types of DC2 nodes:
- dc2.large: This is the first type of dc2.large node requiring 2 virtual CPUs. It also requires 15 GB, and it uses 160GB of storage. The total capacity of this is 5.12 TB.
- dc2.8large: This is the second type of dc2.8large node; it requires 32 virtual CPUs. It also requires 244 GB, and it uses 2.56 TB of storage. The total capacity of this is 326 TB.
- dc1.large: This is the third type of dc2.large node; it requires 2 virtual CPUs. It also requires 15 GB, and it uses 160 GB of storage. The total capacity of this is 5.12 TB.
Example:
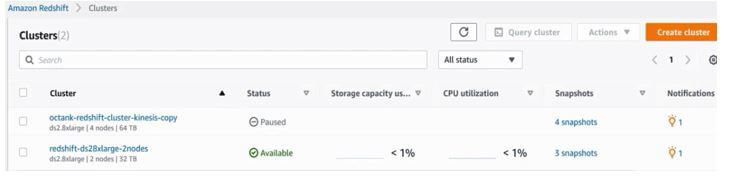
Similarly, we can create a new node that is dc2 with 2 nodes and 32 TB storage inside the cluster by following the same process as RA3. For example, the below screenshot is shown the DC2 node as follows.
3. Dense Storage Node (DS2)
DS2 permits you to have a capacity serious information stockroom with CPU and RAM included for calculation. DS2 hubs use HDD (Hard Disk Drive) for capacity, and as a general guideline, if you have information over 500 GB, it is fitting to go for DS2 examples.
Given below are the types of DS2:
It has two types:
- ds2.xlarge
- ds2.8xlarge
The working of these two types is the same as we have already seen.
Conclusion
The above article shows the basic concept of Redshift node types and the different Redshift node types. From this article, we have seen how and when we use the Redshift node types.
Recommended Articles
This is a guide to Redshift Node Types. Here we discuss the introduction and different Redshift node types for better understanding. You may also have a look at the following articles to learn more –

