Updated May 25, 2023

Definition of Linux HugePages
In this article, we will learn about a management system in Linux that mainly drives memory management. Through this article, we will talk about ways of enabling or disabling Hugepages in Linux, determining the value of a huge page, and much other intricate information. So, formally defining a huge page is a utility that drives virtual memory management in the Linux system. And as the name itself suggests, “huge” sized pages, which are in addition to the standard 4KB page size, can be managed using the concept. One can easily handle pages as huge as 1GB. Now, one must be wondering which pages require such a large size, and to answer that, we have an example just for you! Think about using a database with a high requirement of memory.
Syntax of Linux HugePages
There is no particular fixed syntax for huge pages. But according to the usability of the user, there are a bunch of them, which we will discuss in this section. The first refers to the usability of checking the current huge page details. The syntax for the same is:
grep Huge /proc/meminfoOnce the user has checked for details, one would need to know the number of huge pages the system currently requires. There is also a script in Oracle which we will describe in the example section. If configuration modifications are required after the user has reviewed the details, they can be made in the file “/etc/sysctl.conf.” After changing the variable in that file, use the following syntax to reload the configuration:
sysctl -pApart from syntaxes, one must also be wary about changing the configuration. Additionally, once the configuration changes have been made, it is crucial to restart the application to ensure that the effects of the configuration are applied.
How does HugePages Work in Linux?
Now, it is time to understand the working of hugepages in Linux. In modern-day architecture, multiple page size support is provided; for example, x86 CPUs can support 4K and 2M page sizes (if architectural support is available, 1G page size is also supported), whereas ia64 supports 4K, 8K, 64K, 256K, and so on. There are many such examples. Hugepages have something known as a translation lookaside buffer (abbreviated as TLB) which facilitates caching of virtual to physical translations. With bigger and bigger physical memory now getting available, optimizing the scarce TLB resource in supporting hugepages is becoming more critical.
Now that we have a fair idea of the importance, it is very important to know some common parameters so as to make the flow of information in subsequent paragraphs seamless. HugePages_Total is one such parameter that mentions the size of the pool of huge pages. HugePages_Free represents the number of hugepages in the pool that has yet to be allocated. HugePages_Rsvd specifies the number of reserved large pages, although these pages have not yet been allocated and are just “reserved.” HugePages_Surp is the number of “surplus” pages over and above the current hugepages the system requires.
Now the reserved hugepages return to the pool of hugepages when freed up by a task. Once the allocation is complete, a user with privilege as appropriate can use either map system call or calls from a shared memory system for using huge pages. When the nr_hugepages option changes, the administrator can allocate persistent hugepages on the kernel boot line command. This allocation can free up hugepages as well if required.
The NUMA memory policy specifies these nodes. In case of unavailable continuous memory while the allocation of the huge pages may result in success or failure of huge page allocation.
Examples of Linux HugePages
In this section, we will go through all the options we discussed earlier through a particular example.
Example #1
Code:
grep Huge /proc/meminfoOutput:
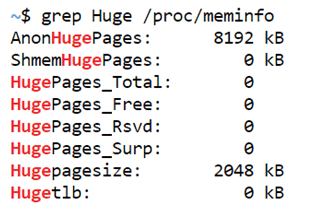
Explanation: By using the grep command, you can retrieve all the details related to hugepages. If all of the properties, such as total hugepages, free hugepages, and so on, are zero, no hugepages are currently assigned.
Example #2
Code:
Enter the command:
vi /etc/sysctl.confInside the conf file:
vm.nr_hugepages=128Close the earlier file and then enter the command:
vi /etc/security/limits.confInside the conf file:
soft memlock 262144
hard memlock 262144Once all modifications have been made, execute the following command:
sysctl -pOutput:
Sysctl.conf file:

Limits.conf file:

Explanation: This is to increase the hugepages from any number to our required number 128.
Conclusion
In this article, we have discussed the usage of hugepages in today’s architecture and how it is becoming increasingly important to have a confident knowledge about these so as to explore the power of hugepages in one’s everyday work. With ever-increasing database size having knowledge about the hugepages is a boon in disguise.
Recommended Articles
We hope that this EDUCBA information on “Linux HugePages” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

